Overview
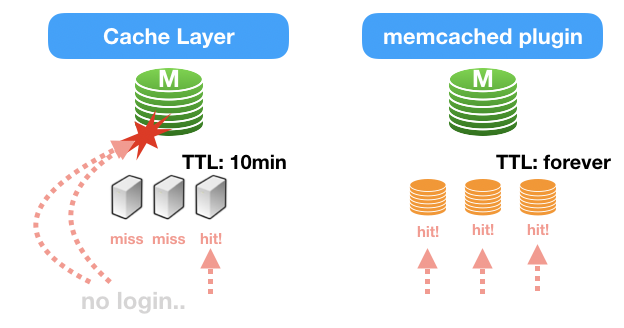
6개월도 훌쩍 넘은 시간에. 간만에 포스팅합니다. 그동안 OGG javaue든, MySQL Binlog파서든.. 흐르는 데이터를 핸들링하는 고민으로 하루하루를 지내왔던 것 같아요. 그러던 중 이전 포스팅에서 주제로 삼았던, InnoDB memcached plugin을 Binlog parsing을 통해 데이터를 맞추면 좋을 것 같다는 생각이 들었습니다.
오늘 이 자리에서는 이런 답답함을 극복하고자, Binlog 이벤트를 활용하여, 최신 데이터를 유지시키는 방안에 대해서 이야기를 해보도록 하겠습니다.
MySQL Binary log?
MySQL에서 데이터복제를 위해서는 Binnary Log(binlog)를 쓰게 되는데, 이중 ROW 포멧으로 만들어지는 이벤트를 활용하여 다양한 데이터 핸들링이 가능합니다.
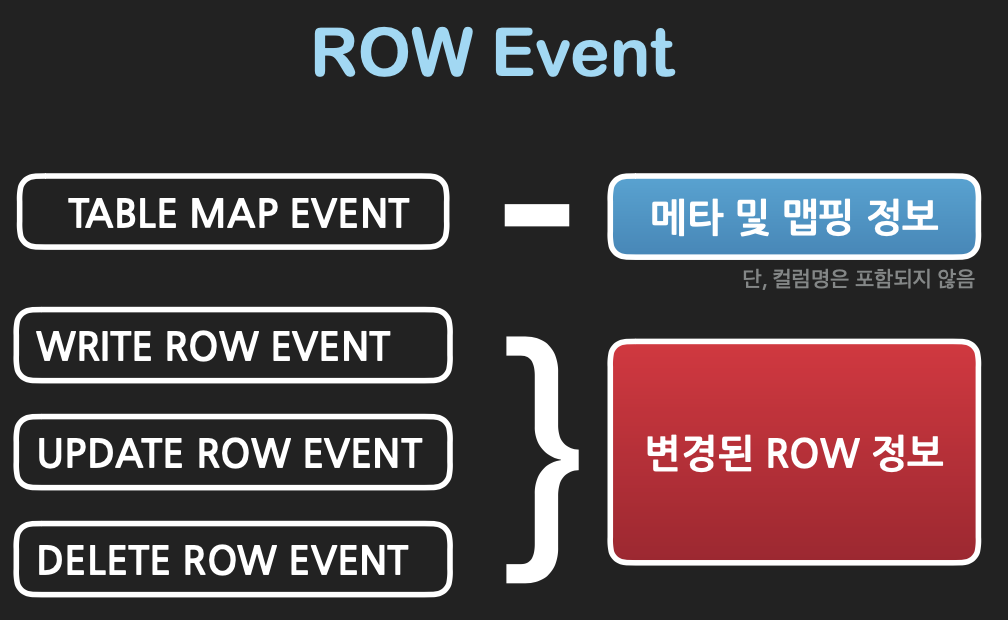
ROW Event는 특정 테이블에 대한 정보를 알려주는 Table map event가 우선 선행하고, 해당 테이블과 연계된 데이터가 뒤따르게 됩니다. 참고로, (InnoDB에서) 트랜잭션 처리가 이루어지면 아래와 같은 이벤트로 바이너리 로그에 기록이 됩니다.
[SQL Event] begin;
[TABLE MAP Event] tableA
[WRITE ROW Event] data[]
[WRITE ROW Event] data[]
[WRITE ROW Event] data[]
[TABLE MAP Event] tableB
[UPDATE ROW Event] <data[], data[]>
[UPDATE ROW Event] < data[], data[]>
[XID Event]그리고, MySQL에서는 binlog_row_image 에 따라 전체데이터(FULL)로 기록할 것인지, 최소한의 정보(MINIMAL)만 기록할 것인지 설정할 수 있습니다.
"FULL" binlog_row_image
변경 이전/이후 모든 데이터를 기록하게 되는데, 많은 정보가 포함되어 있는만큼 다양한 핸들링을 해볼수 있습니다만.. 바이너리 로그 사이즈가 지나치게 커질 수 있다는 리스크가 있습니다.
게시판 조회수를 예로 들자면.. 게시물내용과, 게시물조회수가 동일한 테이블에 있는 상황이라면, 단순히 조회수 1이 증가할 뿐인데.. 이에 대한 바이너리 로그에는 게시물내용까지 포함되어 기록되는 결과로 이어집니다. (잘나가는 사이트에서는 환장할지도 몰라용.)
"MINIMAL" binlog_row_image
변경된 데이터와 PK 데이터만 포함하는.. 정말 최소한의 데이터만 바이너리로그에 기록합니다. 이렇게되면, 로그 사이즈 리스크에서는 자유로워졌지만.. 자유로운 데이터 핸들링에서는 아무래도 제약이 있을 수밖에 없습니다.
참고로, FULL이든 MINIMAL이든, 어떤 칼럼들이 변경되었는지에 대한 정보를 BIT SET로 묶어서 TABLE MAP Event에 포함시켜 전달을 하죠. MINIMAL 이미지 에서도 제대로 처리하기 위해서는 이녀석을 잘 보고, 정말로 변경된 칼럼을 잘 선별해야 합니다. 🙂
Binlog parser & Memcached plugin
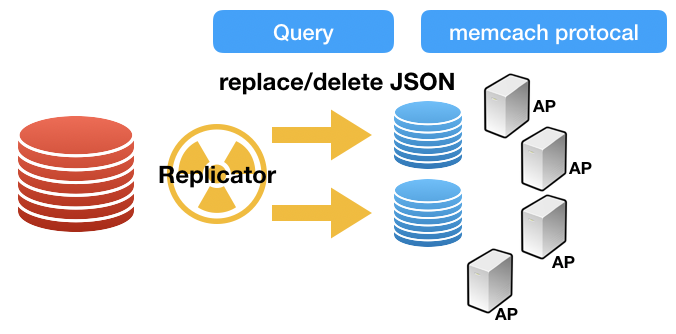
자! Binlog 포멧에 대한 구구절절한 이야기는 이정도로 하고, MySQL Row format의 이런 특성을 통해서 무엇을 상상해볼 수있을 지 이야기를 해보도록 하겠습니다. (바로 아래와 같은 상상?)
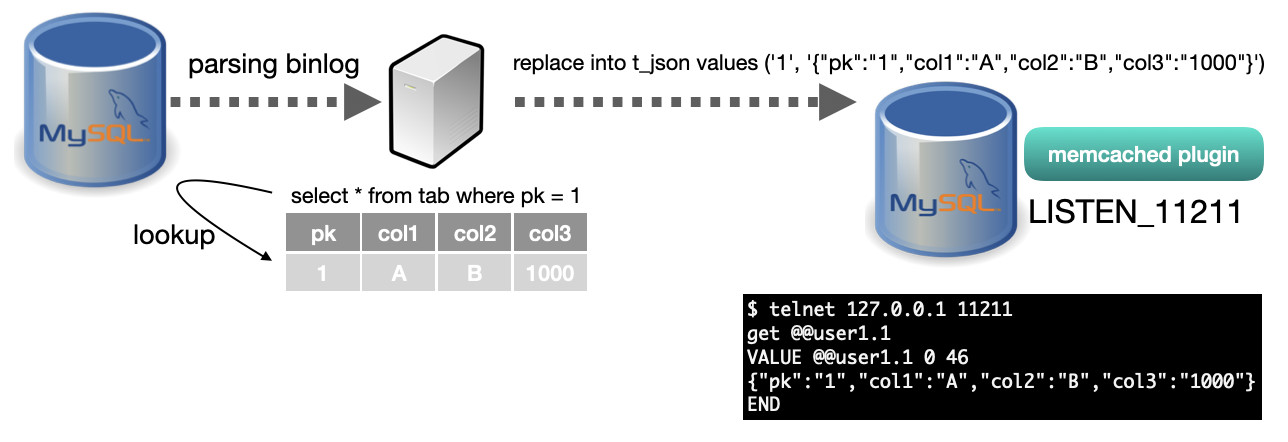
이런 구조에서 고민을 해야할 것은 두가지 정도라고 생각하는데요.
1. DDL 작업
기존 서비스DB에, Memcached plugin 설정 시 칼럼 맵핑 작업을 통해, 여러 칼럼들을 묶어서 memcache protocal에 실어나를 수 있습니다만.. InnoDB plugin으로 인한 대상 테이블에 대한 DDL 제약이 생각보다 많이 생기게 됩니다.
2. 최신 캐시 데이터
캐시서비스를 운영한다면, 가장 최신의 데이터를 캐시에 유지하는 것이라고 포인트라고 개인적으로 생각합니다.
그런데, ROW format에는 어떤 경우는 PK에 대한 정보는 반드시 포함이 되어 있다고 했죠! 그렇다면, 위 그림과 같이, Binlog 이벤트를 받으면, 전달받은 PK를 기반으로 소스DB에서 데이터를 SELECT하고, 결과를 JSON으로 변환해서 타겟DB에 덮어쓰는 것은 어떨까요?
스키마로 묶여있던 칼럼들을 JSON으로 변환(스키마리스)해서 넣기 때문에, DDL 작업으로부터 자유롭습니다. 그리고, 데이터 변경 시 소스에서 가장 최신의 데이터로 적용하기 때문에, 데이터 일관성 측면에서도 유리합니다. (Binlog에 저장된 순으로 데이터를 기록하게 되면, 결과적으로 변경되는 과정이 사용자에게 노출될 수도 있겠죠?)
Binlog이벤트를 받아서, 최신 데이터를 JSON형태로 유지를 시키면, 어플리케이션에서는 그냥 memcache protocal을 통해 데이터를 GET만 하면, 굉장히 빠른 속도로 데이터 처리가 가능해지는 것이죠.
참고로 MySQL InnoDB memcached 플러그인에 대한 내용은 예전에 시리즈로 포스팅을 한 적이 있습니다. (그냥 참고삼아.ㅎ)
- 1탄 MySQL InnoDB의 메모리 캐시 서버로 변신! – 설정편 –
- 2탄 MySQL InnoDB의 메모리 캐시 서버로 변신! – 모니터링편 –
- 3탄 MySQL InnoDB의 메모리 캐시 서버로 변신! – 활용편 –
uldra-binlog-json-transfer
최근 밤에 잠이 잘 안와서, 간단하게 구현해보았습니다. 개인적으로 CDC관련된 자체 아류작이 워낙 많다보니.. 이제는 하루이틀 집중하면, 간단한 처리 구현은 아예 찍어내고 마네요. -_-;;
https://github.com/gywndi/uldra-binlog-json-transfer

Conclusion
MySQL Binlog 이벤트 처리를 활용하여 Memcached 데이터를 잘 응용해볼 수 있는 방안에 대해서 정리해봤습니다. 그리고, 고민의 결과는 이미 위에서 깃헙에 공유를 해놓았고요. ^^
uldra-binlog-json-transfer로 만든 내용은 아래와 같습니다.
1. MySQL Binlog parser
2. PK로 소스 테이블에서 데이터 SELECT
3. 결과를 JSON으로 변환하여 타겟DB에 저장
프로토타입 수준으로 만들어놓은 프로젝트이기에.. 지적질 환영이고, 의견 교류 너무 좋아하고 환장합니다. 🙂
다들 코로나 멋지게 극복하세요.