Overview
대용량 로그 테이블은 때로는 서비스에 지대한 영향을 미치기도 합니다. 게다가 이 테이블을 파티셔닝 구성을 해야하는데, 이를 서비스 운영 중인 상태에서 마스터 장비에서 Import하는 것은 사실 대단히 위험한 시도이기도 하죠.
이런 상황에서 얼마 전 FederatedX엔진을 활용하여 9억 데이터를 이관한 사례가 있는데, 이에 대해 공유하도록 하겠습니다. ^^
Goal
9억 건의 데이터를 Import하는 동안 서비스에는 어떠한 영향도 없어야 하며, 구성 후 어플리케이션 적용 전까지 데이터가 정상적으로 동기화되어야 합니다.
- 데이터 이동하는 동안 기존 서비스 영향 최소화 및 문제 발생 시 빠른 원복
- 데이터 구성 후 어플리케이션 코드 배포 전까지 데이터 동기화
- 데이터 보관 주기 정책에 따른 유연한 대처
현재는 삭제 주기가 없으나, 추후 정책에 따라 변경 가능
Let me SEE..
가야할 골이 정해졌으니.. 현재 상황에 대해서 분석을 해봐야겠죠. ㅎㅎ 다음은 DB 사용 현황에 대한 내용입니다.
1) 소스 서버
- Engine : InnoDB
- QPS(Except SELECT) : 200qps, (MAX)500qps
- 대상 테이블
- download_log – 76G / 3.8억
- open_log – 96G / 5.5억
2) 타겟 서버
- Engine : TokuDB
- QPS(Except SELECT) : 150qps, (MAX)300qps
서버 트래픽이 크지는 않지만, 9억 건 이상의 데이터를 타 서비스 DB로 마이그레이션을 해야하는 상황이었습니다. 그렇기에 서비스에 어떠한 영향도 없어야하며, 문제 발생 시에도 빠르게 롤백할 수 있는 방법이 되어야만 합니다.
How to Migrate?
이런 상황에서라면, 타겟 마스터 장비를 소스 마스터 혹은 슬레이브 장비와 리플리케이션을 걸어서 특정 테이블만 데이터 싱크를 맞추는 방법이 있겠습니다.
그러나, 9억 건 이상의 데이터이고, 서비스 영향없이 마스터 장비로 데이터를 넣어야 하기 때문에.. 목적에 적합한 방법은 아닌 듯 하네요. 슬레이브를 활용하고자 해도, 멀티 소스 리플리케이션을 활용할 수 있는 상황도 아니었으며, 기존 서비스 리플리케이션을 건들여야하기 때문에 깔끔해 보이지는 않았고요.
그래서 아이디어를 낸 방법이, 슬레이브 장비에 FederatedX 스토리지 엔진 전용의 MySQL 데몬을 하나 더 띄워서 데이터 이관을 하는 것이었습니다. 서비스 투입 직전 데이터 흐름을 간단하게 그림으로 표현해 보았습니다.
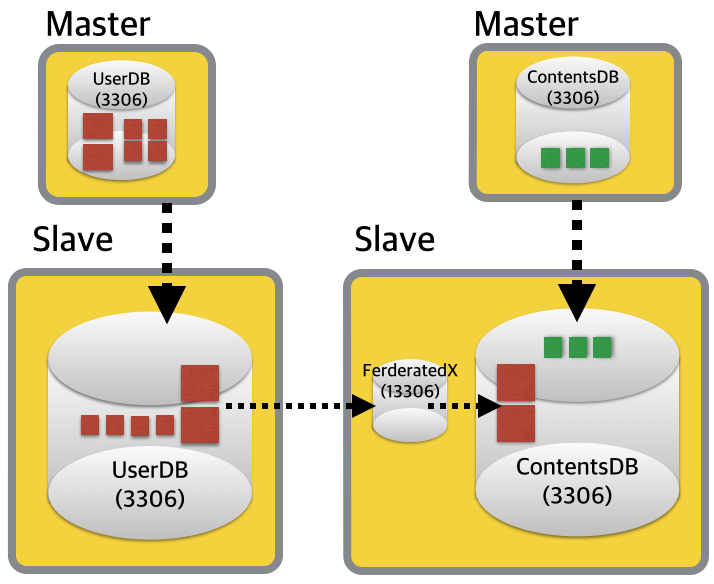
그렇다면, FederatedX? 뭐냐고요?
바로 이전 포스팅에서 이럴줄 알고 슬쩍 정리를 해봤습니다. ^^ 아래 링크를 쿡~!!
>> https://gywn.net/2014/12/let-me-introduce-federatedx/
자~! 그렇다면.. 데이터 이관에 대해 차근차근 단계적으로 설명하도록 하겠습니다.
- Data Dump Backup
- Table Creation
- Data Import & Sync
- Master/Slave Switching
- Slave Restore
1) Data Dump Backup
첫 번째 단계입니다. 옮길 대용량 테이블은 두 개이고, 조금이라도 빠르게 데이터를 이관하기 위해서 각 테이블 별로 덤프 파일을 생성합니다. 두 개의 덤프 파일이 모두 동일한 바이너리 로그 포지션을 가져야하기 때문에, UserDB 쪽 슬레이브의 SQL_Thread를 일시적으로 중지 후 포지션을 기록합니다.
>> UserDB Slave (상단 이미지 왼쪽 아래 서버)
슬레이브 시작 시 영향도를 최소화하기 위해, 슬레이브의 SQL Thread만 중지합니다. 그리고 현재 바이너리 로그 포지션을 기록해놓습니다.
mysql> stop slave sql_thread; Query OK, 0 rows affected(0.00 sec) mysql> show master status; +------------------+----------+ | File | Position | +------------------+----------+ | mysql-bin.006027 | 18752723 | +------------------+----------+
>> ContentsDB Slave (상단 이미지 오른쪽 아래 서버)
UserDB 슬레이브 장비에 3306으로 붙어서 직접 데이터를 받아옵니다. 사실 UserDB에서 로컬로 데이터를 내릴 수 있겠지만, 파일로 전송하는 단계를 생략하기 위함입니다.
$ mysqldump -udumpuser -pdumppass \ --single-transaction --no-create-info \ --add-locks=false -h user-slave \ --databases user_db --tables open_log \ > /backup/open_log.sql & $ mysqldump -udumpuser -pdumppass \ --single-transaction --no-create-info \ --add-locks=false -h user-slave \ --databases user_db --tables download_log \ > /backup/download_log.sql &
아참, 덤프하기 전에 dumpuser를 사전에 생성을 해놔야한다는 사실을 잊으면 안되겠죠. ^^
>> UserDB Slave (상단 이미지 왼쪽 아래 서버)
자~ 이제 덤프가 시작되었으니.. UserDB 쪽 슬레이브를 재계합니다.
mysql> start slave sql_thread; Query OK, 0 rows affected(0.00 sec)
2) Table Creation
FederatedX는 원격의 테이블을 연결시켜주는 실체가 없는 브릿지 역할을 합니다. 즉, “원격 테이블”과 “형상 테이블” 모두 생성을 해줘야하는 것이죠.테이블 스키마 생성 작업은 모~두 서비스와는 전혀 연관이 없는 ContentsDB 슬레이브(상단 이미지 오른쪽 하단)에서 이루어집니다.
>> 원격 테이블 – 3306포트
먼저, 원격 테이블을 생성합니다. 추후 효과적인 데이터 관리를 위해 파티셔닝 설정도 이 기회에 같이 합니다. ㅎㅎ
CREATE TABLE download_log (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT,
user_id int(11) unsigned NOT NULL,
pid bigint(20) unsigned NOT NULL DEFAULT '0',
sid bigint(20) NOT NULL DEFAULT '0',
download_dt datetime NOT NULL,
val1 varchar(45) NOT NULL DEFAULT '',
val2 varchar(45) NOT NULL DEFAULT '',
PRIMARY KEY (id, download_dt),
KEY ix_userid (user_id, download_dt)
) ENGINE=TokuDB AUTO_INCREMENT=400000000
/*!50500 PARTITION BY RANGE COLUMNS(download_dt)
(PARTITION PF_201306 VALUES LESS THAN ('2013-07-01'),
PARTITION PF_201312 VALUES LESS THAN ('2014-01-01'),
PARTITION PF_201406 VALUES LESS THAN ('2014-07-01'),
PARTITION PF_201412 VALUES LESS THAN ('2015-01-01')) */;
CREATE TABLE open_log (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT,
user_id int(11) unsigned NOT NULL,
pid bigint(20) unsigned NOT NULL,
sid bigint(20) NOT NULL DEFAULT '0',
product_type char(4) NOT NULL DEFAULT '',
open_dt datetime NOT NULL,
PRIMARY KEY (id, open_dt),
KEY ix_userid_productid (user_id, open_dt)
) ENGINE=TokuDB AUTO_INCREMENT=600000000
/*!50500 PARTITION BY RANGE COLUMNS(open_dt)
(PARTITION PF_201306 VALUES LESS THAN ('2013-07-01'),
PARTITION PF_201312 VALUES LESS THAN ('2014-01-01'),
PARTITION PF_201406 VALUES LESS THAN ('2014-07-01'),
PARTITION PF_201412 VALUES LESS THAN ('2015-01-01')) */;
>> 형상 테이블(FederatedX) – 13306포트
UserDB로부터 받아온 데이터를 ContentsDB로 전달하는 FederatedX 테이블 스키마입니다. 원본 서버와는 완벽하게 같을 필요는 없으나, 만약 바이너리 로그가 SQL기반으로 기록된다면, 관련 인덱스를 어느정도 맞춰놓는 것이 좋습니다. 여기서는 생략~!
CREATE TABLE download_log ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT, user_id int(11) unsigned NOT NULL, pid bigint(20) unsigned NOT NULL DEFAULT '0', sid bigint(20) NOT NULL DEFAULT '0', download_dt datetime NOT NULL, val1 varchar(45) NOT NULL DEFAULT '', val2 varchar(45) NOT NULL DEFAULT '', PRIMARY KEY (id) ) ENGINE = FEDERATED connection='mysql://feduser:fedpass@127.0.0.1:3306/contents_db/download_log'; CREATE TABLE open_log ( id bigint(20) unsigned NOT NULL AUTO_INCREMENT, user_id int(11) unsigned NOT NULL, pid bigint(20) unsigned NOT NULL, sid bigint(20) NOT NULL DEFAULT '0', product_type char(4) NOT NULL DEFAULT '', open_dt datetime NOT NULL, PRIMARY KEY (id) ) ENGINE = FEDERATED connection='mysql://feduser:fedpass@127.0.0.1:3306/contents_db/open_log';
아참~! 3306 포트로 올라와있는 서버에는 feduser/fedpass로 생성된 유저가 있어야 합니다. 슬레이브가 READ_ONLY일테니 SUPER권한과 함께.. (슬레이브 READ_ONLY를 풀 수도 있겠지만.. 이보다는 전용 DB 접속 유저에 권한을 주는 것이 더 좋을 듯 하네요. ^^)
지금까지 단계가 완료되면, ContentsDB에는 다음과 같이 서버가 구성이 되어 있겠네요.
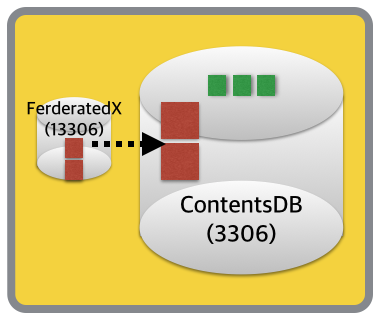
3) Data Import & Sync
옮겨야할 데이터도 있고 옮길 그릇도 있으니, 이제 실제 데이터 이관 작업 후 데이터 동기화를 하는 작업만 남았겠네요. ^^
mysql -ufeduser -pfedpass contents_db < /backup/open_log.sql & mysql -ufeduser -pfedpass contents_db < /backup/download_log.sql &
시간이 꽤 걸리는 이 작업이 완료가 되면, 이제 FederatedX가 떠있는 DB에 접속하여 슬레이브 구성을 합니다.
## replicate_do_table 설정 mysql> set global replicate_do_table = 'user_db.download_log,user_db.open_log '; ## 슬레이브 설정 mysql> CHANGE MASTER TO MASTER_HOST='use-slave', MASTER_PORT= 3306, MASTER_USER='repl', MASTER_PASSWORD='xxxxxx', MASTER_LOG_FILE='mysql-bin.006027', MASTER_LOG_POS=18752723; ## 슬레이브 시작 start slave;
이 과정까지 되면, 제일 처음 표현했던 이미지대로 데이터가 흐르게 됩니다.
4) Master/Slave Switching
가장 트래픽이 적은 시점에 ContentsDB 쪽 마스터/슬레이브 장비를 스위칭합니다.
MHA같은 솔루션을 사용하고 있다면, 더욱 쉽게 마스터/슬레이브 스위칭이 이루어질 것이고, 스위칭 직후에는 아래와 같은 형태로 데이터가 흐르게 되겠죠. 아참, 스위칭 전에 반드시 다음 단계에서 진행할 슬레이브 복구를 위해, 백업을 해주는 것이 좋겠네요.
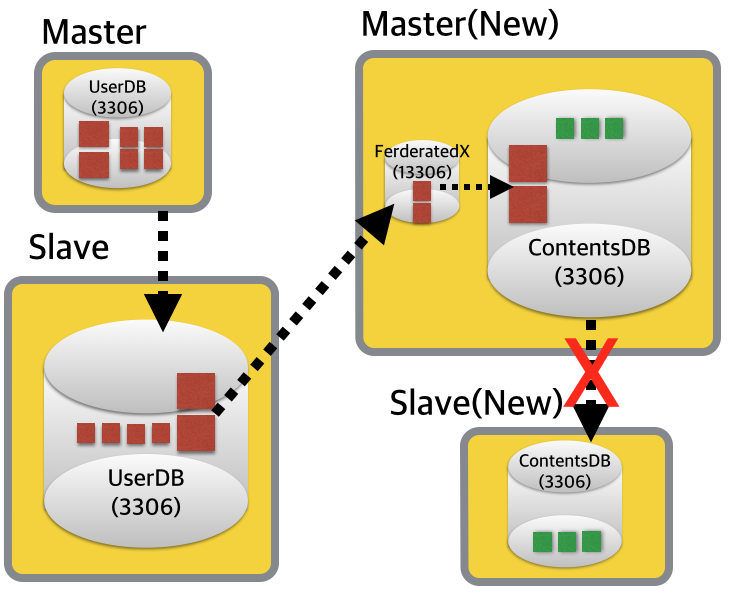
당연한 이야기겠지만, 로그 테이블들이 신규 슬레이브(구 마스터)에는 없기 때문에 ContentsDB 쪽 마스터/슬레이브는 끊어지겠죠.
5) Slave Restore
스위칭 직전 백업 데이터로, 끊어진 슬레이브를 연결합니다. 그리고, 어플리케이션에서 UserDB에 위치한 로그 테이블을 더이상 참조하지 않는 시점에 로그 테이블을 제거하도록 합니다. 이 시점에서는 더이상 FederatedX 테이블도 필요 없기 때문에, 13306포트로 구동 중인 DB서버를 셧다운하도록 합니다.
최종적으로는 대형 로그 테이블이 타 DB로 이관이된 아래와 같은 모습이 됩니다. (휴~! 끝)
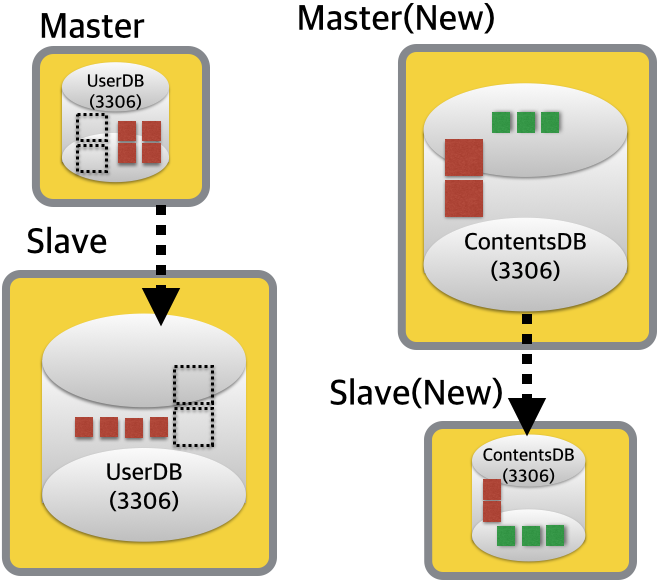
마스터/슬레이브 스위칭 시 순단 현상은 있었겠지만, 적어도 9억 데이터를 이관하는 동안 어떠한 영향도 없었습니다.
Result
InnoDB를 TokuDB로 이관을 하면서 디스크 사용률이 30% 이하로 줄었습니다. TokuDB에 대한 설명은 굳이 여기에서 하지 않아도 될 것 같네요. ^^ 만약 궁금하시다면, 아래 포스팅 내용을 참고하세요.
https://gywn.net/2014/05/fractal-index-in-tokudb/
이관 후 데이터 사이즈는 다음과 같습니다.
- download_log
– 76G -> 21G - open_log
– 96G -> 23G
파티셔닝 구조로 변경하면서, 데이터 보관 주기에 정책에 따라 유연하게 데이터를 유지할 수 있게 되었습니다.
참고로, FederatedX에서 슬레이브를 연결한 직후 동기화 되는 최대 속도는 다음과 같습니다. TokuDB Small 포멧임에도 단일 쓰레드로 3000 query 이상을 발휘합니다.
| Com_insert | 3268 | | Com_insert | 3255 | | Com_insert | 3223 | | Com_insert | 3200 | | Com_insert | 3233 |
Conclusion
지금까지 FederatedX를 사용하여 9억건 데이터를 타 DB로 이관한 사례를 정리하였습니다.
물론, 굳이 이 방법이 아니라고 하더라도 대형 테이블을 타 DB로 이관할 수 있는 방법은 있겠죠. Tungsten Replicator와 같은 솔루션을 활용하거나, 혹은 개발 부서의 적극적인 지원을 받거나..^^
잘 활용되지 않는 FederatedX 엔진이라고 할 지라도, 이러한 용도로 활용을 한다면 꽤 난감한 상황(이를테면 DB 혹은 테이블 명이 변경되는)에서도 유연하게 대처할 수 있겠습니다. 때마침 좋은 사례가 있어서 공유 드립니다.
간만의 포스팅이라 내용이 매끄럽지 않네요. 게다가 하나하나 모두 설명하기에는 무리가 있어서.. 많은 부분을 생략하기도 했고요. ㅠㅠ 기회가 된다면, 이에 대해 조금 더 자세하게 정리할 수 있는 자리가 있으면 좋겠습니다.ㅎㅎ
