Overview
정말 오랜만에 글을 써봅니다. 은행이 오픈한지도 어언 8개월째를 훌쩍 접어들었네요. 여전히 MySQL 서버군에는 이렇다할 장애 없이, 무난(?)하게 하루하루를 지내고 있습니다.. (아.. 그렇다고 놀고만 있지는 않았어요!!)
사실 그동안의 경험과 삽질을 바탕으로, 필요성을 느꼈던 다양한 부분을 중앙 매니저에 최대한 녹여보았고, 그 집대성의 결과가 지금 뱅킹 MySQL시스템입니다. MHA 관리, 스키마 관리, 파티션 관리, 패스워드 관리, 백업/복구 관리..아.. 또 뭐있더라.. -_-;; 암튼, 귀찮은 모든 것들은 최대한 구현을 해놓았지요.
그러나, 예전부터 늘 부족하다고 생각해왔던 한가지 분야가 있는데.. 그것은 바로 모니터링입니다. 시스템에 대한 가장 정확한 최신 정보는 바로 모니터링 지표입니다. 만약, 제대로된 모니터링 시스템 환경 속에서, 실제 서비스의 영속성과 시스템의 매니지먼트를 “모니터링 지표”를 통해서 제대로된 “에코 시스템”을 구축할 수 있다면? 등골이 오싹할 정도의 선순환 작용으로 엄청 견고한 시스템을 구축할 수 있겠죠.
그래서, 한동안 관심가지는 분야가 바로 모니터링, 그중 Percona에서 오픈소스로 제공하는 PMM 요 녀석입니다. 우선은 서두인만큼.. 간단하게 PMM 소개를 해보고, 무엇이 부족한지 썰을 풀어보도록 하겠습니다.
PMM?
PMM(Percona Monitoring and Management)은 Prometheus 기반의 모니터링 솔루션입니다. 바로 몇년전 Percona 의 블로그에 이 관련해서 내용이 포스팅된 적이있었고, 한번 해보고 “와~” 하고 넘어갔었는데.. (은행 구축단계라..쿨럭)
(https://www.percona.com/blog/2016/02/29/graphing-mysql-performance-with-prometheus-and-grafana/)
Prometheus의 여러 프로젝트를 Percona 엮어 재구성 하고, 필요한 것들은 추가로 구현하요 Docker 이비지로 배포하고 있는 녀석이 바로 PMM입니다. ^^
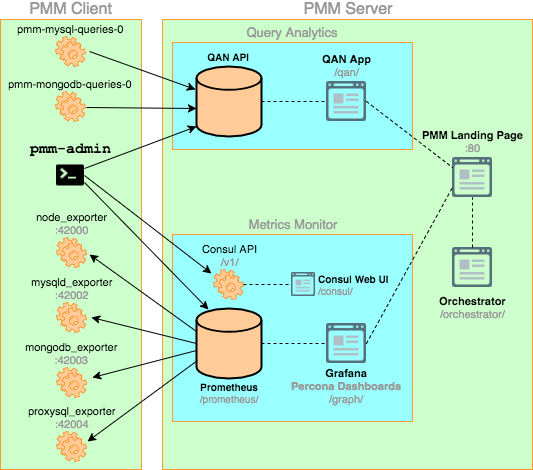
뭔가 굉장히 복잡해 보입니다만.. 여기서 중요한 것 몇가지만 추려본다면..??
1. node_exporter, mysqld_expoter
모니터링 대상 노드(서버)에 서버에 데몬 형태로 구동되는 에이전트입니다. Prometheus에서 에이전트 포트로 매트릭 요청을 하면 즉각 서버의 현 상태를 보내는 역할을 합니다. Percona에서 Prometheus의 exporter를 (아마도) 포트떠서 구현해놓은 듯 하군요.
<Prometheus 프로젝트>
https://github.com/prometheus/node_exporter
https://github.com/prometheus/mysqld_exporter
<Percona 프로젝트>
https://github.com/percona/node_exporter
https://github.com/percona/mysqld_exporter
node_exporter쪽은 제대로 보지 않았지만, percona의 mysqld_expoter는 아래와 같이 크게 세 가지로 나눠서 매트릭을 제공한다는 점에서 기존 Prometheus와는 큰 차이가 있습니다. (참고로, Prometheus는 Parameter 전달 형식으로 매트릭을 선별하여 제공합니다.)
- mysql-hr (High-res metrics, Default 1s)
Global Status / InnoDB Metrics - mysql-mr (Medium-res metrics, Default 5s)
Slave Status / Process List / InnoDB Engine Status.. etc - mysql-lr (Low-res metrics, Default 1m)
Global Variables, Table Schema, Binlog Info.. etc
자세한 것은 하단 깃헙 142 라인부터 확인을 해보세요. ㅎㅎ
https://github.com/percona/mysqld_exporter/blob/master/mysqld_exporter.go
참고로, 저기 나열되어있다고, 모두 활성화해서 올라오지 않습니다. exporter의 구동 파라메터에 따라 선별되어서 수집이 됩니다.. (예를들어 Query Digest 정보는 기본 수집되지 않습니다.) /etc/init.d 하단에 위치한 에이전트 구동 스크립트를 보시면 될 듯..^^
2. pmm-admin
각종 exporter들을 구동 및 제어를 하는 녀석입니다. pmm-admin은 노드 관리를 효과적으로 하기 위해, PMM에 포함된 Consul 서버에 exporter 에이전트 접속 정보(아이피와 포트)를 등록합니다. Prometheus는 매 수집주기마다, Consul 에 등록된 에이전트 리스트를 가져와서 모니터링 매트릭을 수집합니다.
3. pmm-mysql-queries
DB 혹은 OS의 매트릭 정보들은 Prometheus에서 수집/저장을 합니다. 오로지 매트릭만.. -_-;; Prometheus의 동작과는 별개로, DB 서버에서 pmm-server로 데이터를 던지는 녀석이 있는데, 이것은 유입 혹은 슬로우 쿼리에 대한 정보입니다. QAN API로 데이터를 던지는데.. pmm-server의 80포트 /qan-api에 던지면, nginx가 이 데이터를 받아서, 127.0.0.1:9001로 토~스 하여 최종적으로 쿼리를 수집하는 과정을 거칩니다.
한마디로, 쿼리 수집을 위해서는 “[ DB ] –80–> [ PMM ] 형태로 포트 접근이 가능해야한다” 합니다. ㅎㅎ
물론, Prometheus로만으로도 얼마든지 수집이 가능합니다만.. Percona에서 제공하는 QAN 플러그인을 활용할 수 없다는.. -_-;; 쿨럭 사실.. QAN 하나만으로도 블로그 한두개 나올 정도이니.. 나중에 얘기를 해볼께요.
4. Prometheus
타임시리즈 기반의 저장소로, 사실상 PMM의 핵심입니다. 데이터 수집을 비롯해서 저장 그리고 쿼리 질의, Alert까지.. 에이전트의 포트에 접근해서, 모니터링 시스템의 매트릭을 Pull 방식으로 끌어오는 역할을 하지요.
https://prometheus.io/docs/introduction/overview/
앞에서 간단하게 Consul에 대해서 얘기를 했었는데.. pmm-admin이 pmm의 consul에 모니터링이 될 대상들의 아이피와 포트 번호를 넣어주면, Prometheus는 이 정보를 바탕으로 등록된 scrape_interval마다 각 DB서버 에이전트에 접근하여 모니터링 지표를 수집합니다.
- job_name: mysql-hr
scrape_interval: 1s
scrape_timeout: 1s
metrics_path: /metrics-hr
scheme: http
consul_sd_configs:
- server: localhost:8500
datacenter: dc1
tag_separator: ','
scheme: http
services:
- mysql:metrics
이것 외에도 Grafana에서 지표를 보여줄 데이터 저장소 역할도 하며, AlertManager 기능도 제공합니다. Prometheus에 대한 조금더 자세한 설명은.. 훗날(?) 다시 얘기해보도록 하겠습니다. (이거 하나로 책 한권 사실 나옵니다 -_-;; 아놔)
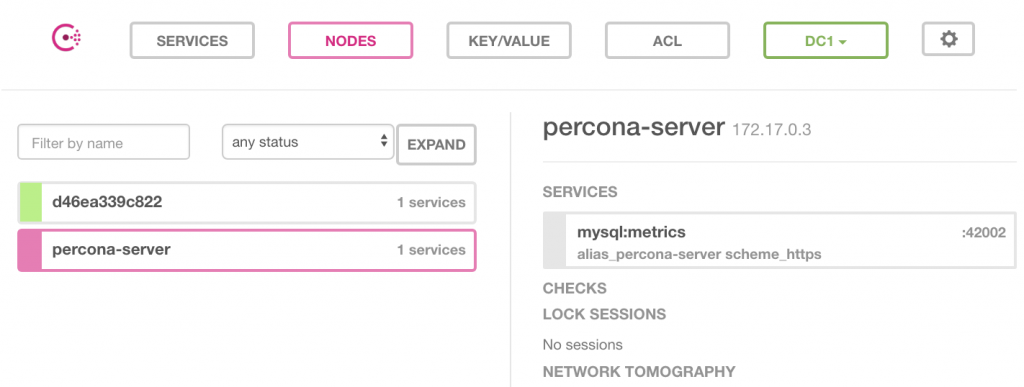
5. Consul
pmm-admin이 consul에 모니터링 대상이 될 장비를 등록하면, 하단과 같이 consul에 저장되고, prometheus는 이 에이전트에 접속하여 매트릭을 수집합니다.
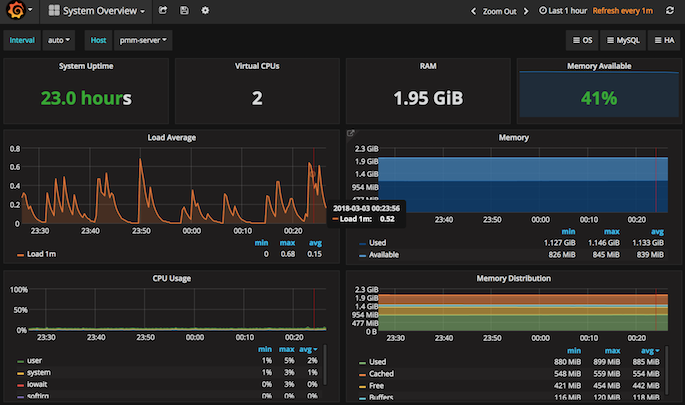
6. Grafana
데이터의 핵심이 Prometheus였다면, Visualization의 핵심은 바로 Grafana입니다. PMM이 강력한 이유가 바로 이미 만들어져 있는 다양한 Grafana 대시보드라고 생각합니다. 적어도 지표를 보여주는 부분에서는 타의 추종을 불허합니다. ^^ 특히나, 내가 원하는 그래프를 내 뜻대로 추가로 마음껏 만들 수 있다는 점에서는 더욱 매력적이죠.
Grafana 에서도 나름의 Alert을 설정하고 보낼 수 있습니다만.. Template Variable을 사용할 수 없기 때문에.. 각 지표마다, 각 서버마다 모두 수작업으로 한땀한땀 등록해야하는 노고가.. (향후 Template Variable을 사용할 수 있게 개선된다고는 하는데..흠..)
https://www.percona.com/blog/2017/02/02/pmm-alerting-with-grafana-working-with-templated-dashboards/
상단 링크를 읽어보면, 어떤 상황인지가 확 와닿을듯.^^
7. Orchestrator
MySQL의 Mater/Slave 토폴리지를 그려주는 녀석으로.. 아직까지 주의깊게 구성해보지는 않았습니다. 수십, 수백대 관리를 고려해봤을때.. 왜 해봐야할지 당위성을 가질 수 없더군요. 그래서 팻패스
Problem
PMM의 구성요소들을 쭉 열거해보았습니다만.. 사실.. 저것 요소 하나하나가 굉장히 큰 꼭지예요. ㅠㅠ 가장 만만한 exporter 하나하나도 해당 시스템 세세한 부분까지 수집하는 큰 프로젝트입니다. ㅠㅠ
아무튼, 지금까지 이것저것 해본 결과에 따라 현재 대단히 부족한 점 몇 꼭지를 콕 찝어서 얘기를 해보도록 하겠습니다.
1. 알람 발송
냉정하게 얘기하자면, 현재 PMM에서는 시스템 문제 시 알람을 효과적으로 발송할 수 없습니다. 나름 Grafana의 Alerting 기능을 통해서 흉내 정도 낸 것같은데.. 실무 적용에는 턱없이..아니 절대 불가합니다. 앞서 얘기한 것 처럼, 모든 지표와 인스턴스에 따른 임계치를 한땀한땀 등록하면 가능하겠지만.. 이건 인간이 할 일은 아니겠죠?
가장 좋은 방안은 Prometheus의 AlertManager를 활용하는 것인데.. ㅎㅎ
2. 수집 주기
수집 주기를 유연하게 변경할 수 있는 Docker 파라메터가 부족합니다. PMM에서 기본 수집 주기는 linux/mysql-hr은 1초, mysql-mr은 5초, mysql-lr은 1분입니다. 사실 10대 미만만 모니터링한다면, 이 수집 주기에 큰 이슈는 없습니다만.. PMM 서버 한대에 20대 이상의 모니터링 대상들을 붙이기 시작하면, 대 재앙이 펼쳐집니다. (로드 20,30,40 펑! ㅋㅋㅋ)
문제는 Docker 이미지로만 제공되는 PMM에서, Docker 컨테이너 초기화 시 옵션 제어가 제한적이라는 점에 있습니다. 실제 PMM Docker 컨테이너의 /opt/entrypoint.sh를 확인해보면.. 그나마 1초 수집주기 항목만 1~5초 사이로 조정할 수 있는 정도로만 구현해놓았습니다. -_-;; 뷁!
# Prometheus
if [[ ! "${METRICS_RESOLUTION:-1s}" =~ ^[1-5]s$ ]]; then
echo "METRICS_RESOLUTION takes only values from 1s to 5s."
exit 1
fi
sed -i "s/1s/${METRICS_RESOLUTION:-1s}/" /etc/prometheus.yml
3. 익명 로그인
이건 당췌 이유를 알 수 없습니다. PMM에 포함된 Grafana 기본은 익명 사용자도 로그인 없이 지표 확인이 가능하게 되어 있습니다.
https://github.com/percona/pmm-server/blob/master/playbook-install.yml 의 209 라인을 보면 분명 의도적으로 로그인 없이도 접근 가능하도록 설정합니다. (왜?)
- name: Grafana | Enable Anonymous access
when: not grafana_db.stat.exists
ini_file:
dest: /etc/grafana/grafana.ini
section: auth.anonymous
option: enabled
value: true
4. 진짜 대시보드
진정한 의미의 대시보드가 없습니다. 특히나, 장애 알람 기능이 현재 전무하기 때문에, 현 시점 이상이 있는 시스템을 재빠르게 캐치할 수 있는 방안이 없습니다. 즉, 지표 보기는 굉장히 최적화가 되어 있습니다만, 문제 발생 시 빠른 감지 및 정보 제공 측면에서는 굉장히 취약한 상태라고 봐야겠지요, ㅜㅜ
참고로, 제가 원하는 대시보드는 아래와 같은 모습이며, 특정 서버 문제 시 바로 현황 파악이 가능한 모습입니다.
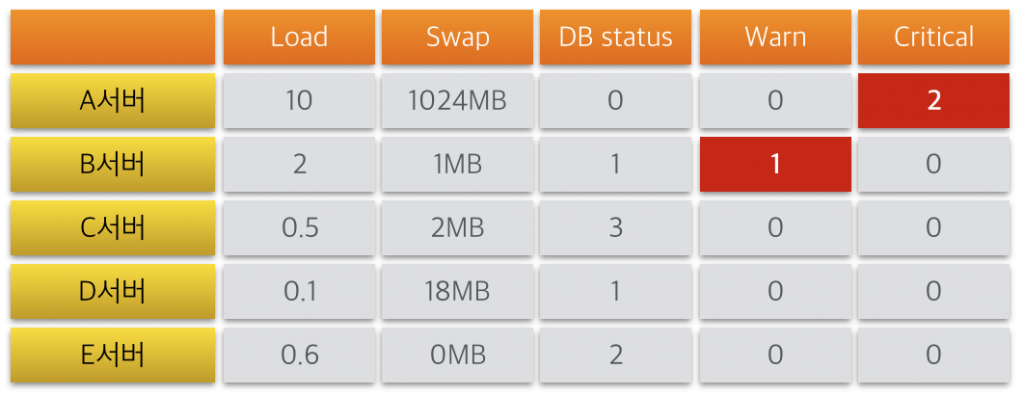
5. Grafana Sqlite
PMM에 포함된 Grafana는 모든 메타 정보(대시보드를 포함한 지표 정보)를 SQLite에 저장합니다. 사실, 지표에 별다른 수정없이 기본값 그대로 사용한다면 큰 문제는 없지만.. 그렇지 않다면 생각보다 꽤나 많은 부분을 변경해야합니다. ㅠㅠ JSON 스트링 그대로 SQLite TEXT컬럼에 저장되어 있기 때문에.. 의외로 대량 편집에 상당 부분 노고가 필요합니다. 게다가.. 데이터 잘못 삭제 시.. 복구 방안은?? -_-;;
PMM안에도 mysql 이 기본 설치되기 때문에.. 이왕이면 이 녀석을 잘 활용했으면 하는 바램이;; 쿨럭 (무엇보다, 이럴꺼면, mysql5.7의 json 타입을 활용해보면 어떨까 생각도 합니다.)
Conclusion
Percona는 PMM을 Docker 이미지로 배포합니다. 사실 Docker로 배포되지 않는다고 한다면, 나름 커스터마이징이 용이할 것 같다는 생각은 듭니다만.. Percona에서 기능 구현 후 새로운 Docker를 배포한다고 생각해봤을 때, 자칫 잘못하면 그간의 노고가 한방에 날라갈 수 있겠습니다.
즉, 개인적인 생각이기는 하지만.. Docker 컨테이너를 임의로 수정하기 보다는, 최대한 PMM 의 흐름에 맞춰서 필요한 부분을 취하는 것이 현명할 것이라 생각합니다. 물론 필요하다면, Percona도 설득도 해봐야겠죠. ^^
우선, 당장은 PMM을 실무에 바로 적용하기에는 무리가 있습니다..만.. 이 부족한 부분을 기존 소스 흐름에서 크게 벗어나지 않는 수준으로 어떻게 대안을 찾아가고 있는지.. 다음 블로그부터 하나하나 정리를 해보도록 하겠습니다.
(참고로, 앞선 문제점들은 대나름의 해결 방안을 만들어놓았습니다. ㅎㅎ)
일단, PMM 서버 구성을 해봐야겠죠? ^^