처가 과수원 사과 수확을 하고 왔습니다. 매주 빡빡한 스케줄.. 연예인 못지않군요.^^ 그렇지만, 오늘도 역시.. SQLite 시리즈를 이어보겠습니다. ^0^ (힘들어서 2회에 걸쳐서 진행하겠습니다. ^^)
Overview
어떤 DBMS를 막론하고, Searching은 가장 중요한 요소입니다. 특히 데이터 건 수가 많을수록, 원하는 데이터를 찾아내기 위해 처음부터 끝까지 모두 파일을 뒤지게 된다면.. 쿼리 시간을 떠나 사용하는 전력 또한 상당할 것입니다. 특히 SQLite가 모바일 환경에서 대부분 활용된다는 상황에서, CPU 자원을 최소화한다는 것은 결과적으로 배터리 소모를 최소한으로 이룰 수 있음을 의미하죠. ^^
그래서 오늘은 SQLite에서 발생하는 Searching에 대해 포스팅을 하도록 하겠습니다.
Full Scan
풀스캔입니다. DBMS를 막론하고, 데이터 사이즈가 커질수록 “반드시” 지양해야 하는 스캔이죠. 풀스캔은 말 그대로, DB 테이블에 포함된 데이터를 처음부터 끝까지 체크하며 원하는 데이터를 추출하는 것을 의미합니다.
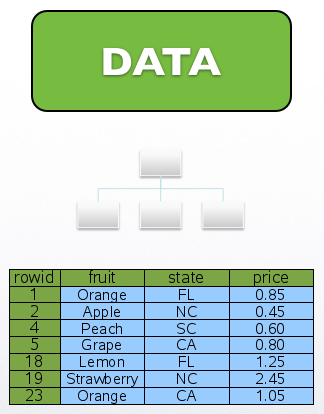
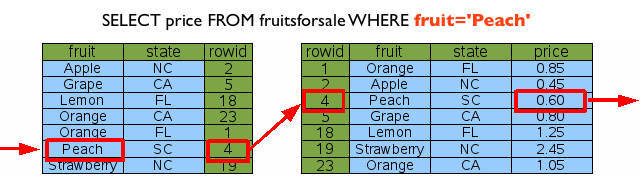
적절한 인덱스가 없는 경우에 발생하는데, 데이터를 RowID순으로 접근하며 테이블 데이터를 추출하죠. RowID란 SQLite 2탄 – 데이터와 인덱스 구조!!에서 소개드린 것처럼, 각 행 특정한 행에 접근하기 위한 “주소”와 동일한 역할을 하는 8Byte의 정수 키 값입니다. ^^
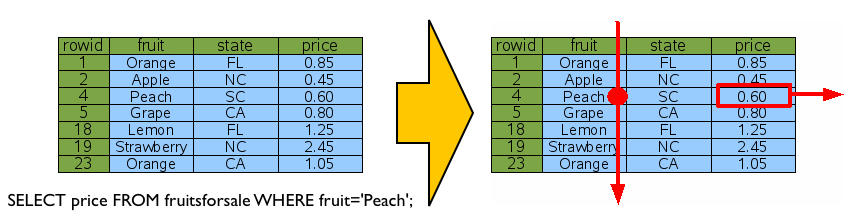
위 그림에서 fruit에 해당하는 인덱스가 없는 경우 RowID 순으로 처음부터 끝까지 fruit이 ‘Peach’인 데이터를 찾아서 결과를 리턴하게 되죠. 이것이 바로 풀스캔입니다. ^^ 쿼리 성능이 느리다면, 적절한 인덱스가 없어서 풀스캔이 발생하고 있는지를 확인하세요.
Lookup By RowID
바로 앞에서 설명한 풀스캔은 일반적으로 데이터가 커질수록 데이터 추출이 가장 느린 스캔 방법입니다. 그렇다면, 이것과는 반대로 아무리 데이터가 많아도 가장 빠른 데이터 추출을 방법은 무엇일까요? 그렇습니다. 바로 “RowID”로 접근하여 데이터를 바로 추출하는 것입니다.
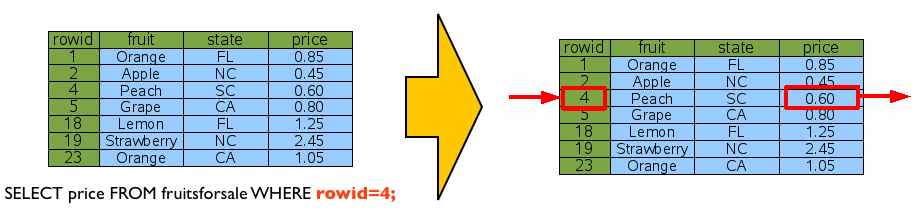
RowID가 테이블 데이터의 위치를 지칭하는 주소와 같은 역할을 하니, 당연히도 가장 빠른 데이터 접근방법일 수밖에 없겠죠. ^^;
Lookup By Index
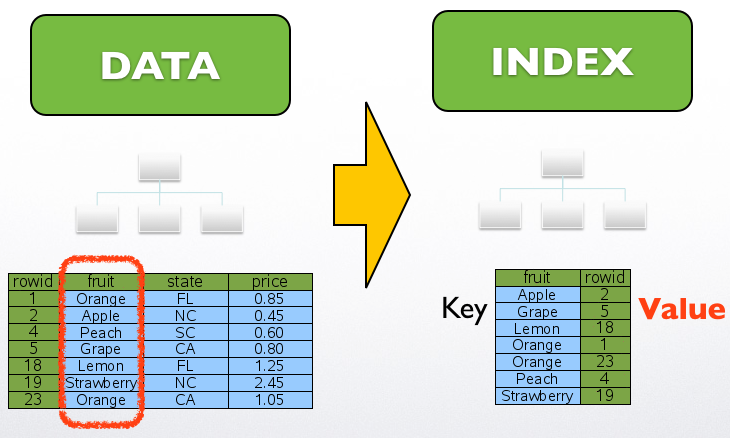
자~! 효율이 가장 떨어지는 것은 풀스캔이고, 가장 빠른 접근은 RowID를 통한 것인데.. 이 둘을 먼저 설명드린 이유는 바로 인덱스에 대한 얘기를 하기 위함입니다. 인덱스는 마치 책 가장 뒷편에 위치한 색인과 같은 의미로, 데이터가 위치한 주소를 저장하는 자료 구조입니다. 바로 이전 포스닝 SQLite 2탄 – 데이터와 인덱스 구조!!에서 인덱스의 구성에 대해서 간단하게 말씀드린 바 있습니다. SQLite에서 인덱스는 인덱싱할 칼럼을 “키”값으로, 그리고 접근할 데이터의 RowID를 “값”으로 “B-Tree”로 구성됩니다.
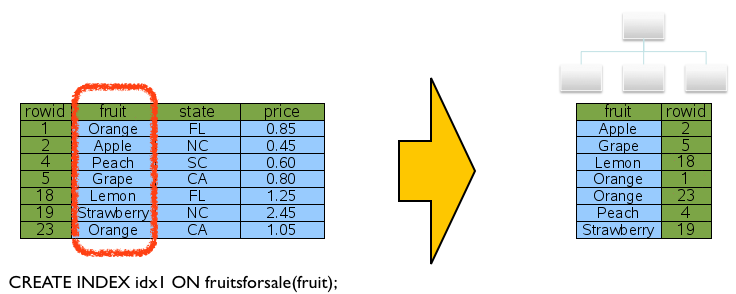
위 그림은 인덱스를 생성을 하였을 때 인덱스 데이터 구조에 대한 모습이며, 인덱싱한 칼럼을 기준으로 각각의 RowID가 저장되어 있는 것을 확인할 수 있습니다. ^^
데이터에의 접근은 두 단계로 이루어집니다. 먼저, 검색할 데이터를 기준으로 인덱스 데이터에 접근을 합니다. 만약 데이터가 있다면, 인덱스 Value인 RowID를 기준으로 이번에는 데이터 트리에 접근하여 최종적으로 원하는 데이터를 추출하는 것이죠. 자, 아래 그림을 보시죠. ^^
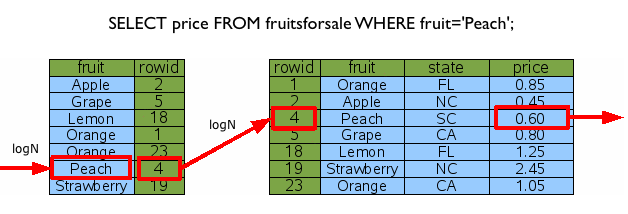
먼저 앞서 생성한 인덱스 자료 구조에 접근하여, RowID를 가져와서 실제적으로 원하는 데이터를 추출하는 단계를 보여줍니다. 앗! 그런데 저기서 logN은 무엇이냐고요? 특정 요청을 처리 시 소요되는 비용을 의미하는데, 트리에서는 평균적으로 logN번 과정을 거쳐서 원하는 데이터에 접근하게 되는 것이죠. 자세한 설명은 생략하겠습니다. ^^;;
위 그림에서 트리의 한 건 데이터에 접근하는 비용이 logN이고, 인덱스로 걸러지는 데이터가 K건이라면 (1+K)*logN 의 비용이 발생하게 됩니다. 수식이 나오니, 조금 어지럽군요. @.@ 다시 이에 대한 것을 그림으로..(역시 사람은 가시적인 것이 쵝오!! >_<)
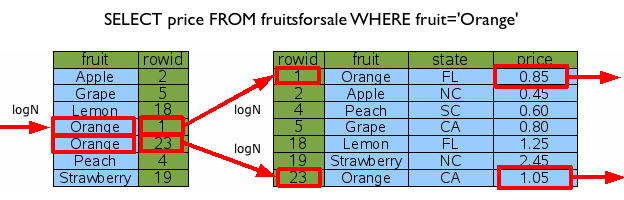
오렌지에 걸러지는 데이터가 두 건이고, 이 두 건을 각각 데이터 트리로 접근하기 때문에 (1+2)*logN의 비용이 발생하는 것을 보여줍니다. ^^;
자! 그렇다면, 만약 인덱스 칼럼과 인덱스에 포함되지 않는 칼럼이 동시에 검색 조건으로 들어오면 어떻게 될까요? 과연 인덱스에 포함되지 않는 칼럼이 비용을 줄여주는 역할을 할까요? 아쉽지만, 세상에는 그러한 매직은 없습니다. ㅜㅜ 비용은 바로 이전 ‘Orange’로 검색한 것과 동일한 리소스를 소모하게 되는 것이죠. (1+2)*logN이고, 걸러진 데이터의 state를 다시 한번 판별하고, 원하는 데이터를 추출하는 것이죠.
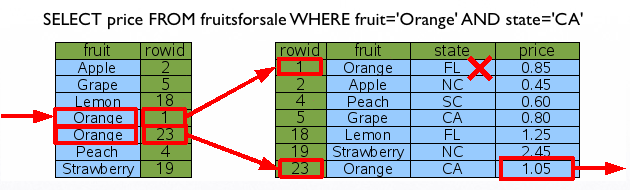
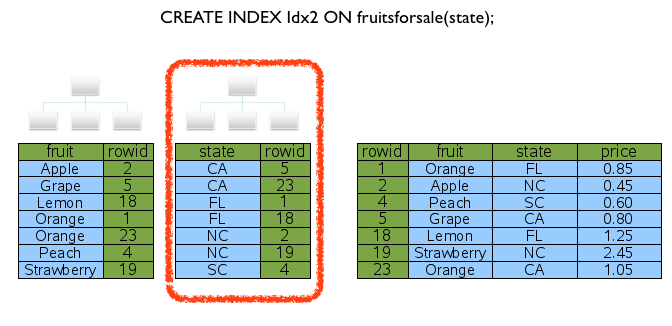
여기서 인덱스에 대한 퀴즈 하나! 위와 같은 상황에서 아래와 같이 state칼럼에 인덱스를 추가한다면, 쿼리 성능이 좋아지는 효과가 있을까요? 즉, 두 개의 인덱스 자료구조를 동시에 참조하여, 단 한번에 원하는 데이터에 바로 접근 가능할까요?
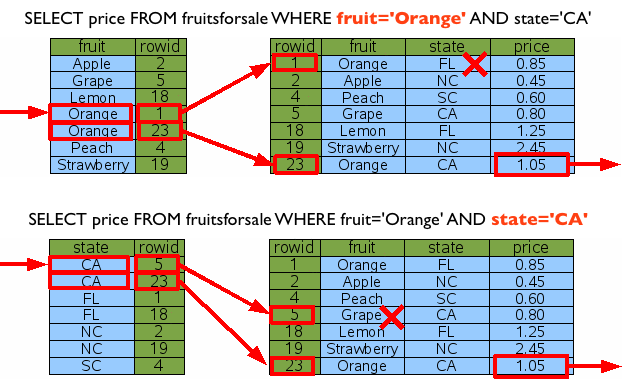
아쉽지만, 이런 마술 또한 SQLite에서는 존재하지 않습니다. ㅜㅜ 아래 그림처럼 fruit 혹은 state 인덱스 중 하나에만 접근하여 데이터에 접근하게 됩니다. 물론, SQLite 내부적으로 분포도를 고려해서 처리되겠죠. ^^
그렇다면, 여기서 fruit와 state 칼럼 모두 포함하는 인덱스를 생성한다면 어떻게 될까요? 아래 그림처럼, 한번에 데이터에 접근하게 됩니다. ^^
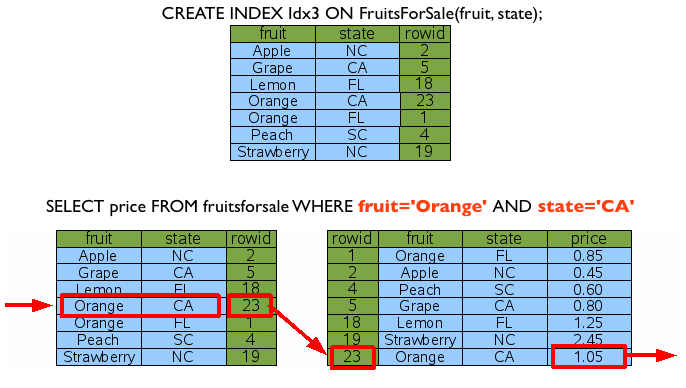
이 경우 앞에서와 같이 fruit에만 조건이 있는 경우를 걱정할 수도 있겠지만, 인덱스의 멋진점은 바로 이것!! fruit로만 조건이 들어와도 데이터를 추출할 수 있습니다.
인덱스를 생성한 칼럼 순서로 Where 조건이 들어오면 정상적으로 인덱스를 타게 되는 것이죠. ^^ 위에서는 (fruit, state) 순으로 인덱스를 생성하였고, fruit이 Where 조건으로 들어왔기 때문에, 정상적으로 인덱스를 활용하게 되는 것이죠.
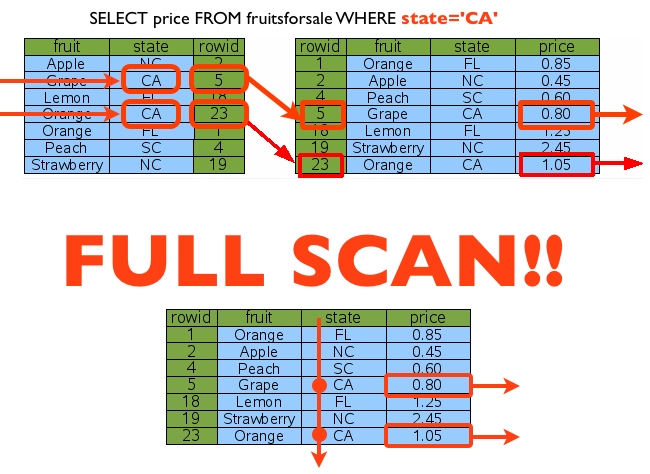
그렇다면, state만 검색 조건으로 들어온 경우는 어떨까요? 과연 (fruit, state)에 걸린 인덱스를 정상적으로 활용할 수 있을까요? (아~! 앞에서 state 칼럼에만 인덱스를 건 경우는 무시해주세요. 없다고 가정하세요. ^^;;)
결론은 “풀스캔”입니다. ㅜㅜ
Conclusion
오늘은 Full-Scan, RowID, Index를 통한 데이터 Searching에 대해 정리해보았습니다. 설명을 더욱 간결하고 쉽게 해야하는데.. 어떠셨는지.. 자~! 여기까지 정리하겠습니다.
- Full-Scan은 RowID 순으로 데이터에 순차적으로 접근하여 원하는 데이터를 추출하는 방식으로 일반적으로 가장 느린 데이터 접근 방식이다.
- 데이터의 위치를 지칭하는 주소 역할을 하는 RowID로 데이터에 접근하는 것이 가장 빠르다.
- 인덱스는 인덱싱할 칼럼을 “키”값으로, 그리고 접근할 데이터의 RowID를 “값”으로 “B-Tree”로 구성된 자료구조이다.
아웅.. 정리하고 나니, 내용이 많지 않네요. ㅜㅜ 오늘 마무리 못한, 데이터 접근에 대한 얘기를 다음번 포스팅에서 남은 이야기를 정리하도록 할께요.