MemSQL이란?
MemSQL은 디스크 병목을 최소화하기 위해 만들어진 메모리 기반의 관계형 DBMS입니다. 메모리 기반으로 데이터 처리가 이루어지기 때문에, 엄청난 속도로 Read/Write이 가능하며, 기존의 NoSQL 또는 캐시로만 가능했던 퍼포먼스 향상이 있습니다. 실제로 디스크 기반 DBMS 대비 약 30배 이상의 성능 향상이 있다고 하니, 놀라울 따름입니다.
![]()
최근 들어 메모리 가격이 하루가 다르게 저렴해지고 있기 때문에 메모리 사이즈를 최대한 늘려서 가격 대비 성능 비를 최대로 이끌어 내는 DB입니다.
MemSQL 특징
1) 강력한 SQL기반의 통신
SQL 기반으로 통신하며, MySQL API를 따릅니다. 그렇기 때문에 기존 MySQL을 사용하는 서비스 경우 로직 변경이 불필요하다고 합니다. 하다못해 라이브러리 또한 기존 MySQL에서 사용하던 그대로 재사용해도 상관 없습니다.

SQL기반이기 때문에 복잡한 데이터 처리에 유연하며, DB 레이어가 구분되므로 어플리케이션에 영향을 의존적이지 않습니다.
사실 NoSQL이 강력한 성능을 발휘하기는 하지만, DB Schema와 같은 기반 요소가 어플리케이션에 녹아있고 사용이 어렵습니다. 그리고 데이터 처리 시 개발자 개인 역량에 따라 전체적인 성능에 엄청난 영향을 주기도 하죠.
2) 내구성이 좋은 구조
MemSQL은 서버가 예기치 않게 종료가 된다고 하더라도 데이터 유실이 거의 없습니다. 서버 장애가 발생한다고 하더라도 Snapshot으로 특정 시점의 풀 백업 데이터와L(Write Ahead to Log)로 쌓인 데이터 변경 이력을 조합하여 “장애 시점 이전”으로 데이터 버전을 되돌릴 수 있습니다.
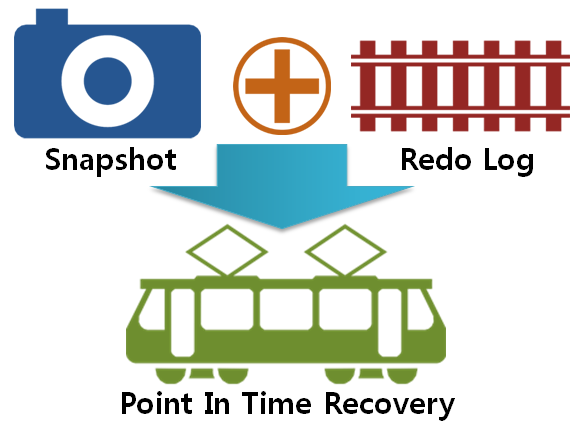
물론 데이터 영속성이 불필요한 프로세스 경우에는 “durability = off” 옵션으로 비활성할 수 있습니다. 하지만, 이 경우 서버 재시작 후 메모리에 있는 모든 데이터는 소멸되므로 사용 시 주의를 해야겠죠. ^^;;
3) 쉬운 설치 및 사용
MemSQL은 설치가 정말로 쉬우며, 관련 Configure 파일도 단순합니다. 그리고 MySQL 진영에서 개발을 했었다면, 쿼리 사용에도 큰 무리가 없습니다.
4) Transaction 기능
MemSQL은 트랜잭션을 단일 쿼리 레벨에서 Read Committed 레벨로 데이터를 처리합니다. 사용자 레벨로는 Transaction을 제공하지 않기 때문에 복잡한 Transaction이 요구되는 부분에서는 분명 한계가 있습니다.
만약 being, commit, rollback과 같은 구문을 어플리케이션에서 사용한다고 하더라도, Warning 메세지와 함께 DB 내부에서 무시됩니다. 즉, 데이터 변경 질의가 완료되는 바로 그 순간 다른 세션에서도 변경된 데이터를 바로 읽을 수 있습니다.
Repeatable Read(Snapshot Read) Isolation Level은 내부적으로 Database Snapshot을 생성하기 위해 사용되는데, snapshot-trigger-size 임계치에 도달하여 새로운 Snapshot을 생성할 때 사용합니다.
5) 동시성과 퍼포먼스를 위한 인덱스 기능
Hash Index
Hash 인덱스는 1:1로 매칭되는 경우 최상의 성능을 발휘하며, Hash 인덱스를 사용하기 위해서는 인덱스 필드에 Unique 옵션이 있어야 가능합니다.고 Hash 인덱스 생성 시 BUCKET_COUNT 옵션을 별도로 줄 수 있고, 512에서 2^30까지 설정할 수 있는데, 데이터 사이즈에 따라 적절하게 파라메터 값을 지정해야 합니다.메터 값이 너무 작으면, Hash 효율이 크게 저하되고, 반대로 너무 크면 Hash Bucket을 위해 메모리가 불필요하게 많이 사용되기 때문이죠.
예를 들어 파라메터 값이 너무 작으면 빨간 색 그림처럼 한 개의 Hash 타겟에 여러 개의 데이터가 포함되어 있으므로, 원하는 타겟 데이터를 선별하는 부분에서 로드가 발생합니다.다고 파라메터를 너무 크게 잡으면 파란 그림처럼 메모리 공간만 잡고 아무 것도 포인팅하고 있지 않는 결과가 발생하죠.
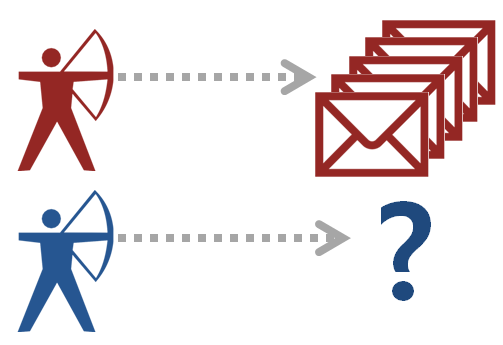
MemSQL측에서는 누적될 수 있는 데이터 최대치 Row 수의 50%로 설정하는 것이 바람직하다고 합니다. 즉, 하나의 Hash키에서는 평균 2개까지 중복되는 것이 성능 및 공간 효율적으로 최적이라는 것을 의미하는 것이죠.
Skip List
B-Tree는 일반적으로 RDBMS에서 제공하는 인덱스 구조이며, MySQL에서도 관련 기능을 제공합니다.
둘의 차이점은 MySQL은 디스크 기반으로 B-Tree를 수행하나, MemSQL은 메모리 기반의 Skip List 구조로 데이터를 찾아냅니다. 데이터 접근 속도가 더욱 빠른 것이죠.
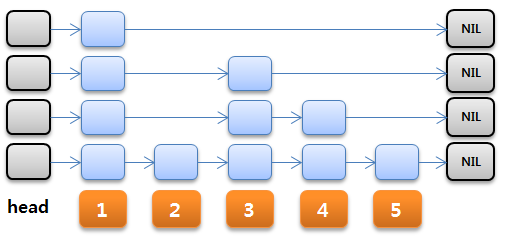
하단과 같이 인덱스를 ASC 옵션으로 생성된 경우, “Order By r ASC”로 Skip List로 빠르게 데이터에 접근할 수 있습니다. 그러나 “Order By r DESC” 경우에는 Skip List를 사용하지 않기 때문에 상대적으로 속도가 느리다고는 합니다.
물론 DESC 옵션으로 추가적인 인덱스를 생성하면 동일하게 Skip List의 강점을 이용할 수도 있겠지만, 인덱스 또한 공간을 잡아먹는 데이터이기 때문에 사용 상 주의가 필요합니다.
memsql> CREATE TABLE tbl (
-> name VARCHAR(20) PRIMARY KEY,
-> r INT,
-> INDEX i USING BTREE (r ASC)
-> );
memsql> EXPLAIN SELECT name FROM tbl ORDER BY r ASC;
+-------------+------+------+-------+
| select_type | type | key | Extra |
+-------------+------+------+-------+
| SIMPLE | ALL | i1 | |
+-------------+------+------+-------+
memsql> EXPLAIN SELECT name FROM tbl ORDER BY r DESC;
+-------------+------+------+-----------------------+
| select_type | type | key | Extra |
+-------------+------+------+-----------------------+
| SIMPLE | ALL | i1 | memsql: requires sort |
+-------------+------+------+-----------------------+
6) SQL을 선행 컴파일하여 처리
SQL 실행 순서는 Oracle과 거의 흡사합니다.
Parse → Code Generate →an Cache →ecute를 거칩니다. Plan Cache에 적재된 SQL 실행 속도는 빠르지만, 처음 실행되는 SQL은 상당히 느립니다.
처리 단계를 조목조목 설명하겠습니다.
- Parse
쿼리가 유입되면 SQL에 포함된 정수 혹은 문자열 파라메터를 특정 문자로 변환하는 과정입니다.
예를 들어 SELECT * FROM users WHERE id = ‘gywndi’;라는 쿼리는 SELECT * FROM users WHERE id = @; 와 같이 변환됩니다.
물론 이 SQL Parsing 단계는 DB에 오버헤드가 거의 없습니다. - Code Generate
Parsing 단계에서 생성된 SQL을 DB가 쉽게 처리할 수 있는 C++ 기반으로 변환하는 단계입니다.
DB에서는 원본 SQL이 아닌 데이터를 조회하기에 최적화된 코드에 따라서 데이터를 질의합니다.
결과는 바로 다음 단계인 Plan Cache 영역에 저장됩니다. - Plan Cache
전 단계에서 컴파일된 실행 계획을 Plan Cache 메모리 영역에 저장하며, 이후 동일한 타입의 SQL 유입 시 SQL 컴파일 단계 없이 Plan Cache에 있는 정보로 바로 처리합니다. - ecute
데이터 추출은 오직 선행 컴파일된 Plan정보로만 수행됩니다.
이제 SQL을 더이상 순차적으로 읽으며 분석하지 않아도 되기 때문에 마치 NoSQL Solution처럼 혹은 그 이상의 속도를 낼 수 있는 것입니다.
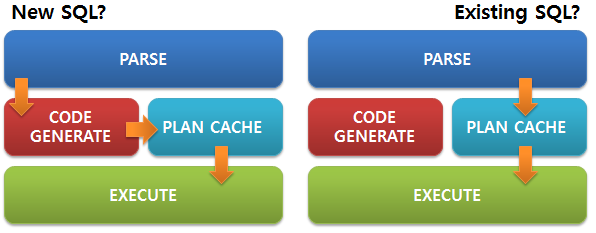
처음 SQL 질의 요청이 들어오면 Parse → Code Generate →an Cache →ecute 단계를 거쳐서 데이터를 뽑아냅니다.
기존에 SQL을 실행하여 이미 Plan Cache에 관련 실행 계획이 저장된 경우에는rse → Plan Cache →ecute 단계로 수행을 합니다. 실행 계획 생성 없이 Plan Cache에 저장된 정보로 바로 데이터를 조회할 수 있습니다.
7) Concepts
메모리 기반의 RDBMS인 MemSQL은 두 가지 컨셉으로 만들어졌습니다. Lock이 없는 Hash인덱스와 Skip List를 활용한 B-Tree인덱스를 사용함으로써 일반 CPU에서도 강력한 데이터 처리가 가능합니다. 그리고 MVCC를 제공하기 때문에 엄청난 Writing이 발생함에도 절대 Reading 시 장애가 발생하지 않습니다.
두 가지 특징에 초점을 맞추어 개발을 하였고, 기존 디스크 기반 데이터 처리 속도 대비 30배 이상 빠르다고 합니다.
MemSQL 테스트 후기
Sysbench 툴을 사용하여 벤치마킹을 시도하려 하였으나, DB 특성이 다르다보니 테스트를 할 수 없었습니다. 대신 다른 몇 가지 부분만 짚어서 단일 쿼리 테스트로 진행을 하였고, 테스트 기간 동안 데이터 현황을 한번 살펴보았습니다.
MemSQL Requirement가 일단은 CentOS 6.0 이상이었고, 해당 OS는 제 개인 블로그 서버에만 설치되어 있었기 때문에 어쩔 수 없이 저사양 PC에서 테스트하였습니다. ^^;;
테스트 환경
- CPU :350 (1.6GHz)
- Memory : 8G
- Disk : 3.5′ SATAII 5400 rpm Single
- Data : 100만 건
Sysbench 툴로 100만 건 데이터를 생성하고, 해당 데이터로 간단한 질의 몇개와 기본적인 차이점을 위주로 살펴보았습니다. MemSQL은 물론 메모리 안에 모두 데이터가 존재하며, MySQL 또한 데이터 사이즈가 크지 않기 때문에 메모리에 전체 데이터가 들어있다고 봐도 무관합니다.

테스트 결과 100만 건 일괄 업데이트에서는 MySQL이 더 빠릅니다. InnoDB Buffer Pool도 결국에는 메모리에 존재하기 때문이 아닐까 합니다. 그리고 업데이트 도중 다른 세션에서는 현재 변경되고 있는 데이터 현황을 확인할 수 없는 것에서 쿼리 단위로 트랜잭션이 보장되는 것을 추측할 수 있었습니다.
MemSQL에서 SQL이 처음 실행되는 순간, 즉 컴파일이 필요한 시점에는 상당히 느립니다. 그러나 동일 타입의 쿼리가 다시 호출되는 경우 MySQL대비 10배 이상 빠른 결과를 보였습니다.
MemSQL에는 Plan Cache가 있는데 이것에 관한 현황은 다음과 같이 조회할 수 있습니다.
memsql> SHOW PLANCACHE\G
************** 1. row **************
Database: sysbench
QueryText: select * from sbtest where id = @
Commits: 113
Rollbacks: 0
RowCount: 2606
ExecutionTime: 5
LogBufferTime: NULL
LogFlushTime: NULL
RowLockTime: NULL
************** 2. row **************
Database: sysbench
QueryText: select k, count(*) from sbtest group by k
Commits: 7
Rollbacks: 0
RowCount: 53
ExecutionTime: 3611
LogBufferTime: NULL
LogFlushTime: NULL
RowLockTime: NULL
************** 3. row **************
Database: sysbench
QueryText: INSERT INTO sbtest(k, c, pad) VALUES (?,?,?)
Commits: 100
Rollbacks: 0
RowCount: 1000000
ExecutionTime: 19503
LogBufferTime: 0
LogFlushTime: 0
RowLockTime: 0
각 정보는 누적된 결과이며, Plan Cache에 들어있으면, 그 이후로는 SQL 실행 시간이 엄청하게 빨라집니다. (1번 쿼리는 평균 0.00005초 미만입니다.)
그러나! 질의를 만드는 도중 몇 가지 제약 사항을 알게 되었는데.. 기존에서 큰 무리가 없던 쿼리 사용이 불가하다는 것입니다.
간단하게 두 개 정도 쿼리 예를 들겠습니다.
memsql> update sbtest
-> set k = cast(rand()*100000 as unsigned);
ERROR 1707 (HY000): This query contains constructs not currently supported by MemSQL. The query cannot be executed.
memsql> select count(*)
-> from (
-> select id from sbtest
-> where id between 1 and 100
-> ) t;
ERROR 1707 (HY000): This query contains constructs not currently supported by MemSQL. The query cannot be executed.
Update쿼리에는 함수가 아닌 상수 값이 지정되어야 하며, 위와 같은 타입의 서브쿼리는 지원하지 않습니다. 즉 MySQL에서 MemSQL로 데이터를 이관한다고 하더라도 상당 부분 SQL 변경을 해야할 것 같네요^^;;
위 두 가지 외에도 더욱 많은 제약 사항들이 있을 것 같네요.
Conclusion
트랜잭션을 지원하는 메모리 기반 DBMS이기 때문에 많은 기대를 하였으나, 서비스에 직접적인 투입을 하기에는 아직까지는 한계가 있어 보입니다.풍부한 기능을 가진 MySQL과 테스트에서는 기능적인 요소 뿐만 아니라 편의성 부분에서도 부족합니다.
MySQL 프로토콜을 사용기 때문에 접근성은 타 NoSQL보다는 수훨하나, 기존 MySQL에서 데이터 이관 시 쿼리 또한 상당 부분 변경이 필요합니다.고 Replicaion 기능과 Sharding에 관한 내용을 MemSQL에서는 소개를 하였으나, 활용할 수 있는 메뉴얼을 현재까지 찾을 수 없었습니다. (현재 개발되고 있는 버전이 아닐까 생각이 드네요.)
하지만 메모리 기반이고, NoSQL보다는 접근성이 뛰어나며 단순 Select 테스트에서도 MySQL대비 10배 이상 빠른 성능을 보인 것으로 보아 지속적으로 눈여겨 볼 필요가 있는 제품일 것 같네요. ^^;**
DB 목적을 정확하게 정의하고 데이터 그룹 메타 정보 보관 혹은 해시 성격의 데이터를 관리하는 시스템에서라면.. (SQL 종류가 다양하지 않은 단순 질의) 꽤나 좋은 성능을 보이지 않을까요?
물론 서비스에 투입하기 이전에 DB 안정성 및 데이터 견고성에 관한 보장이 선행되어야겠죠.^^
참고자료 : href=“http://developers.memsql.com/" target="_blank” rel=“nofollow”>http://developers.memsql.com/