Overview
대부분 서비스에서는 데이터 카운트를 합니다. 커뮤니티에서는 사용자 아티클 수를, 결제 서비스에서는 남은 물폼 수를 관리하기 위해서 사용하죠. 그리고 트랜잭션이 중요한 서비스라면, 데이터 일관성 유지를 위해 카운트 시 매번 데이터를 다시 읽어옵니다.
데이터가 적으면 큰 문제가 되지 않겠지만, 데이터 지속적으로 누적됨에 따라 성능 또한 기하급수적으로 저하됩니다.
그렇다면 이러한 환경에서 어떻게 카운트 퍼포먼스를 향상할 수 있을까요? 오늘 포스팅할 내용은 MySQL뿐만 아니라 행 단위 잠금을 지원하는 환경도 포함합니다.
통계 테이블 사용
빠른 데이터 건 수를 가져오는 방법으로는 별도의 통계 테이블을 관리하는 것입니다. 다음과 같이 통계 테이블을 별도로 구성하여 카운트 정보를 관리합니다.
이렇게 되면, 굳이 덩치가 큰 테이블에서 일일이 카운트를 하지 않고, 통계 테이블에서 한 건의 데이터만 읽어오므로, 카운트 성능을 크게 향상할 수 있죠.
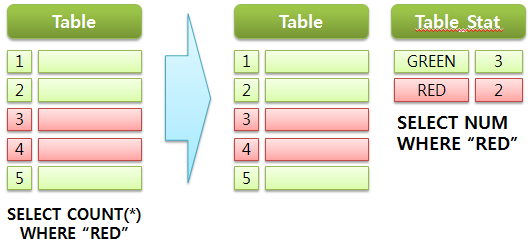
통계 테이블을 운용하는 방법에는 주기적으로 통계 데이터를 업데이트하거나 동일 트랜잭션으로 묶어서 관리하는 방법이 있습니다. 카운트 정보가 서비스에 큰 영향을 미치지 않는다면, 주기적인 업데이트하여 관리할 수 있습니다.
하지만 결제 혹은 선착순 로직처럼 데이터 일관성이 중요하다면, 반드시 실시간으로 데이터 처리가 이루어져야 하죠. 이 경우 동일 트랜잭션으로 묶어서 관리해야 하며, InnoDB에서는 행 단위 잠금으로 동작하므로 트랜잭션이 몰리더라도 데이터 변경 동시성을 어느정도 보장합니다.
하지만 특정 통계 데이터를 동시다발적으로 변경하는 이슈가 발생한다면? 게다가 단위 트랜잭션 성능이 생각보다 좋지 않다면? 예를 들어 대학 수강 신청에서 특정 인기 강좌에 수강 신청이 갑자기 몰리는 경우를 생각할 수 있습니다. 이 경우 DB는 내부 Lock 메커니즘에 따라 물리적 리소스를 전혀 사용하지 않은 채 대기 상태에만 머물어서 전체 서비스에 치명적인 영향을 미칩니다.
그렇다면 이러한 특정 데이터 잠금을 어떻게 회피할 수 있을까요?
단위 트랜잭션 성능을 높여라!
트랜잭션이 중요한 실시간 환경에서 행단위 잠금을 회피하는 첫 번째 단추는 단위 트랜잭션 내 Commit을 가능한 최대한 빠르게 수행하는 것입니다. (당연한 이야기겠지만..) 예를 들어 다음 트랜잭션 상황에서 후행처리 SELECT가 데이터 일관성과 큰 연관이 없다면 트랜잭션 외부로 빼내서 시간을 단축할 수 있겠죠.
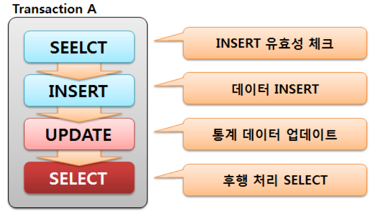 단위 트랜잭션 평균 속도가 0.2초를 0.02초로 줄일 수 있다면, 경합을 최단 기간에 마무리 할 수 있습니다. ^^
단위 트랜잭션 평균 속도가 0.2초를 0.02초로 줄일 수 있다면, 경합을 최단 기간에 마무리 할 수 있습니다. ^^
통계 데이터를 여러 행에 분산 관리하라!
트랜잭션을 아무리 짧게 유도해도, 해당 트랜잭션이 처리하는 동안에는 그 어떤 트랜잭션도 데이터 변경이 불가합니다. 여전히 한 가지 행에 순차적으로 Access 해야 한다는 점에서, 내부적으로 상당한 리소스 비효율이 발생합니다.
그렇다면 다음 그림과 같이 변경 대상이 되는 행을 여러 개로 만들어서 분산 관리하면 어떨까요?
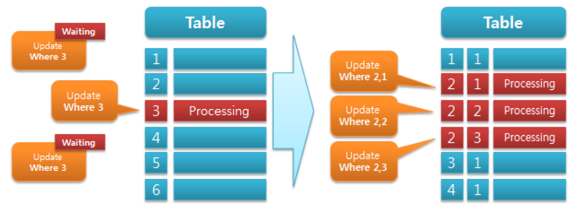
물론 통계 정보 분산 관리를 위해 오른쪽 그림처럼 추가 칼럼이 더 필요합니다. 이 경우 통계 데이터는 Group By 구문을 사용하여 다음과 같이 가져올 수 있습니다. (하단 테스트 스키마 참고) 단, 반드시 Transaction Isolation Level을 READ-COMMITTED로 설정하여 SELECT 해야 잠금 현상이 발생하지 않습니다. ^^ (물론 카운트 정보가 트랜잭션에 직접적인 요소만 아니라면, 상관없습니다.)
select sum(j) j from test where i = 2
여기서 한가지 중요한 것은 Group By 구문을 사용하는 만큼 무조건 많은 행에 분산하는 것을 올바른 방법이 아닙니다. 동시성을 높이기 위해 SELECT 성능을 약간은 희생하므로 적절한 Trade-Off는 스스로 판단하여.. ^^;;
그렇다면 행 단위 잠금을 위와 같이 분산 관리하였을 때 얼마나 데이터 처리 효율이 좋아지는 지 간단한 테스트로 확인해보겠습니다.
테스트
하나의 행에 몰리는 트래픽을 여러 개의 행으로 나누어서 처리했을 때 처리 변화량을 비교하겠습니다. 위와 같은 환경에서 20개의 세션에서 통계 데이터를 단일 행, 여러 행 경우로 나누어서 테스트 수행합니다.
테스트 환경 구성
## 테이블 생성
CREATE TABLE test (
i int(11) NOT NULL,
i2 int(11) NOT NULL,
j int(11) NOT NULL,
PRIMARY KEY (i,i2)
) ENGINE=InnoDB;
## 테스트 데이터 생성
INSERT INTO test VALUES
(1, 1, 0), (1, 2, 0), (1, 3, 0), (1, 4, 0), (1, 5, 0),
(1, 6, 0), (1, 7, 0), (1, 8, 0), (1, 9, 0), (1, 10, 0);
업데이트 되는 행을 다음과 같이 제한하여, 분산 환경을 구성합니다. (명시적으로 보이기 위해서 MySQL rand() 함수를 사용했지만, 실제 트래픽 어플에서 랜덤 값을 구현하세요. 버그가 있는듯..^^)
단, Binary Log를 Statement로 기록하는 경우에는 아래처럼 CRC32()를 사용하지 마세요. 특히 리플리케이션 환경이라면, 마스터 슬레이브 간 데이터가 달라집니다.
## 단일 행
update test set j = j + 1
where i = 1 and i2 = 1;
## 5개 행
update test set j = j + 1
where i = 1 and i2 = cast(rand()*5 as unsigned) + 1
## 10개 행
update test set j = j + 1
where i = 1 and i2 = cast(rand()*10 as unsigned) + 1
성능 테스트 결과
트랜잭션 단위 수행 속도가 0.2초인 경우입니다.
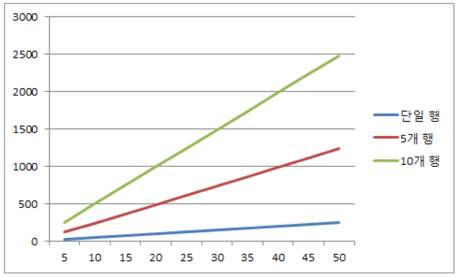
여러 행에 데이터를 분산 업데이트 유도할수록 거의 비례하게 DB본연의 처리 속도가 나옵니다. 그렇다면 불필요한 SELECT를 제거하여 단위 트랜잭션 속도를 0.02초로 줄였다면 어떨까요?
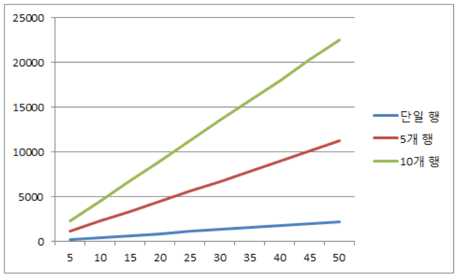
당연한 이야기이겠지만, 앞선 결과 대비 약 10배 이상의 퍼포먼스를 보이죠.^^ Lock 발생이 줄어드는 만큼 DB리소스를 많이 사용하지만, 그만큼 DBMS효율성이 증대하는 것을 의미하죠.
Conclusion
데이터 누적에 따른 카운트 성능을 별도의 통계 데이터를 관리하여 성능 향상을 유도할 수 있습니다. 하지만, 특정 통계 데이터 동시 변경 요청 발생 시 Lock이 발생할 수 있습니다. 이것은 행단위 잠금과는 별개의 Lock 메커니즘에 따른 결과이죠. 이러한 Lock 현상을 다음 두 가지 방법을 최대한 회피할 수 있습니다.
- 단위 트랜잭션 속도 증대
- 통계 데이터를 여러 행에 분산 관리
그렇다고 데이터 처리 동시성을 높이기 위해 약간의 SELECT 성능을 희생하는 만큼 무조건 다수의 행에 분산 관리하는 것은 좋지 않습니다.
트랜잭션이 중요한 서비스에서 적용해볼만한 머리 속에만 있던 간단한 팁을 공유합니다.
감사합니다.