Overview
최근들어 거의 연단위로 블로깅을 하나씩 올리는 듯 하는군요. 여기저기 시국이 어지럽고, 바쁘다는 말도 안되는 핑계를 무마시키기 위해.. 아무튼 간만에 블로깅 하나 올려봅니다.
MySQL은.. 특히나 온라인 스키마 변경이 취약합니다. 물론 5.6부터는 online alter기능이 포함되어 있다고는 하나.. 100% 완벽하게 모든 상황을 온라인스럽게 제공해주지도 않고.. 그렇다하더라도, 일정 트래픽 이상의 데이터 변경이 이루어지는 경우, 게다가 슬레이브 지연을 염두한다면.. 꺼려지는 상황이 있지요. (참고로, 마스터에서 온라인 스키마 변경이 이루어졌을지라도, 이 관련 alter구문이 슬레이브로 넘어갔을 때는, alter이후 데이터 변경을 수행해야 하므로, 그만큼 복제 지연이 발생합니다. 미네럴~)
아무튼.. 이런저런 이유로.. 기승전툴이라는 생각이드는데요. 그중, Percona에서 오픈소스 라이선스로 제공하는 pt-toolkit에 포함된 pt-online-schema-change툴을 저는 애용합니다.
참 좋지만.. 반드시 짚고 넘어가야할 이슈 하나만은 반드시 공유할 필요가 있다는 생각이 들어, 이렇게 늦은 시간 포스팅을 합니다. 🙂
pt-online-schema-change?
문제를 말하기에 앞서서, 먼저 pt-online-schema-change의 동작 방식에 대해서 정말 간~략하게 알아볼 필요가 있겠군요.
이 툴은 서비스 중지 없이 실시간으로 테이블 DDL Alter구문을 적용할 수 있도록 도와주는 하나의 “유틸리티”이며, 흔한 RDBMS에서 제공하는 기능 몇가지와, 머리좋은 개발자의 “꼼수”가 환상적인 조합을 이루며 만들어진 멋진 툴입니다. 짝짝짝~
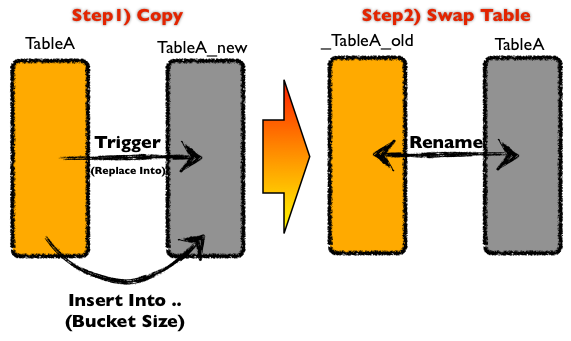
간단한 테이블 변경 순서는 아래와 같아요.
- 클론 테이블 생성 후 의도한 스키마를 적용한다.
- 원본 테이블 변경 시 트리거로 이를 클론 테이블에 적용한다. (replace into/delete)
- 조각 조각 데이터를 잘라서, 데이터를 중복은 무시한 채 복사한다. (insert ignore)
- 테이블 복사가 완료되면, 클론<->원본 테이블명을 스위칭한다.
Percona..당신들의 잉여력은 많은 이들을 행복하게 하였습니다. 땡큐~!!
Problem
물론, pt-online-schema-change도 하나의 툴인 이상.. 분명 100% 모든 상황에 적합하지는 않습니다.
뭐.. 예를 들면.. 아무래도 데이터를 조각조각 나누어서 복사를 해야하는만큼, Primary Key는 반드시 존재해야하는 상황이어야하고, Foreign Key가 정의된 경우에도 제약이 있고.. 궁시렁궁시렁..
그렇지만, 오늘 여기서 짚어보자하는 문제는.. 사실은 pt-online-schema-change가 충분히 동작할 수 있는 상황에서, 데이터가 달라질 수 있는.. 곰곰히 생각을 해보면 서비스 오류까지 발생할 수 있는 그런 상황입니다요.
pt-online-schema-change에서 앞서 설명을 간단하게 했던 것처럼, 트리거를 통해서 현재 데이터 변경된 이력을 클론 테이블(스키마 적용된 최종본 구조 테이블)로 적용합니다. 적용시 insert/update 구문 모두 아래와 같이 replace into 구문으로 대동단결 하는데요. (참고로 _test_tmp는 클론테이블입니다.)
DELIMITER $$
CREATE TRIGGER trg_test_update
AFTER UPDATE ON test
FOR EACH ROW
BEGIN
REPLACE INTO _test_tmp VALUES (NEW.id, .., NEW.created_at);
END$$
DELIMITER ;
동일 트리거이니.. 문제삼을 update 트리거만..
멀쩡한 상황에서는 이슈가 아닙니다만.. 여기서 replace의 동작 방식을 이해하고, 조금만 고개를 갸우뚱거리면 무엇이 문제인지 이해하실 수 있을 것이예요. 귀찮으니, 매뉴얼 원문을 퍼오겠습니다. 크하하
REPLACEworks exactly likeINSERT, except that if an old row in the table has the same value as a new row for aPRIMARY KEYor aUNIQUEindex, the old row is deleted before the new row is inserte
그렇답니다. 기존의 pk/uk와 같이 충돌나는 것들은 다 날리고.. 신규 데이터로 밀어넣는다는 것인데요. 그렇기에 pk가 없으면 대 재앙일 것이고.. 이런 부분에 대해서는 나름 pt-online-chema-change에서 제약 조건을 체크하기는 합니다. (그랬던가.. 가물가물..)
그렇다면.. 이런 경우 말고.. PK가 변경되는 상황을 생각해볼까요? 이런 상황에서도 역시 replace into 구문으로 트리거는 동작할 것이고.. 트리거 내부에는 “NEW.id, .., NEW.created_at”와 같이 변경될 데이터 기준으로 클론 테이블에 적용될 것이고.. NEW.id가 PK라면, 이 기준과 동일한 데이터를 날리고 엎어버릴 것이고..
그렇다면.. 우움.. 기준이 되는 NEW.id가 변경된 경우에는.. -_-;; 예전 OLD.id의 행방은??
딩동댕~ 맞습니다. ㅠㅠ 어이없게도.. 업데이터로 동작을 해야할 상황이.. 기준점이 변경되었다는 이유로.. 여전히 남아있는 상태가 되겠지요. 미네럴2.
즉.. 로직적인 이슈로.. 기준점이 되는 PK를 변경하는 경우 여전히 과거의 이력이 남아있게 되는.. 어이없는 상황이 발생한다는 것입니다!! <==== 주의주의1
Solutions
사실.. 해결책은 의외로 간단합니다.
PK는 업데이트 하지 말고, 트랜잭션으로 묶어서 DELETE -> INSERT 처리한다. 참 쉽죠잉~! 이것은.. 뭐.. 해결방안이라기 보다는 그냥 “우회처리”라고 해야하나.. -_-;;
그치만.. 사용자를 쿼리를 날리는 경우도 있고.. 기타 이런 상황을 인지 못하는 경우를 대비해서.. 본질적인 해결 방안이 필요합니다.
PK가 변경된 경우 트리거 내부적으로 과거 데이터를 날려주는 로직을 넣어준다.
트리거 정의하는 부분에.. PK 변경 시 OLD 이미지에 해당하는 데이터를 날리도록 강제하면 되지요. 뭐.. 아래 예시는.. 쿼리 레벨 간단하게 소스를 약간 수정한 것일뿐.. 조금 수정해서 트리거 내부에 if else 구문을 넣어도 되고..암튼 그렇답니다.
sub create_triggers {
.. 중략 ..
## 추가 ##
my $upd_index_cols = join(" AND ", map {
my $new_col = $_;
my $old_col = $old_col_for{$new_col} || $new_col;
my $new_qcol = $q->quote($new_col);
my $old_qcol = $q->quote($old_col);
"OLD.$old_qcol <=> NEW.$new_qcol"
} @{$tbl_struct->{keys}->{$del_index}->{cols}} );
.. 중략 ..
## DELETE 부분 추가 ##
my $update_trigger
= "CREATE TRIGGER `${prefix}_upd` AFTER UPDATE ON $orig_tbl->{name} "
. "FOR EACH ROW "
. "BEGIN "
. "DELETE IGNORE FROM $new_tbl->{name} WHERE !($upd_index_cols) AND $del_index_cols;"
. "REPLACE INTO $new_tbl->{name} ($qcols) VALUES ($new_vals);"
. "END ";
.. 중략 ..
}
PK가 변경된 경우에는 데이터를 지워버리고, 그렇지 않으면.. 그냥 예전처럼 replace~ 트리거 내부적으로 update시에 쿼리는 많아지겠고, 트랜잭션이 없는 상황에서는 약간 걱정될만한 사항도 있겠지만.. 다들 기본적으로 InnoDB사용하시잖아요? ㅋㅋ
사실.. 이런 부분은 간단하게 소스를 수정해서 활용을 해도 됩니다. 어려운것도 아니고.. 잉여력이 조금 남아있다면 얼마든지 상황에 맞게 고쳐 쓸 수 있겠지요. 그치만.. 이 부분에 대해서 Percona에 문의를 해보니.. 그들의 입장은.. 번역하면 아래와 같았습니다.
어째서 PK가 변경이 되어야하는 것인가? 테이블에서 PK는 절대적이므로, 결코 업데이트 작업이 이루어지지 않아야 한다. 우리들은 이런 현상을 버그로 인정하지 않는다. – 어느 개발자 –
버그가 아니라면.. 이런 상황을 감지해서 제약을 걸든가.. 미네럴3..
사실.. 가장 경계를 해야하는 문제는.. (제 개인적인 의견이지만) 런타임 오류라고 생각합니다. 서비스 오픈 전에 발생하는 모든 이슈는 사전에 불을 끄고 튜닝하고 해결할 수 있지만.. 런타임 도중 특이 케이스에서만 노출되는 이슈는 정말로 답이 없습니다.
위와 같은 동일한 방식은 아니더라도, 적어도 PK변경 시 뒤따르는 이러한 데이터 꼬임 현상에 대한 것들은 Percona 측에서 제대로 이해하고 GE버전에 적용을 해줬으면 하는 마음이 있고.. 뭐.. 개인적으로, 조직적으로 푸시를 넣고 있습니다만..
좋은 소식이 있겠지요. ^^
Conclusion
pt-online-schema-change 툴은 굉장히 유용하고, 제가 정말 자주 쓰는 권고할만한 유틸입니다. 게다가 소스도 오픈되어 있고, 누구나 수정할 수 있는 라이선스 정책이고요.
그렇지만, 오픈소스를 사용하는만큼.. 그렇게 접근을 하기에.. 상용 솔루션과는 다르게 발생하는 이슈에 대해서 분석을 해보고 해결책을 가져가보고, 대안도 고민해보고.. 사용자 자신도 오픈소스를 사용하는 대가를 치뤄야 하겠지요. 뭐.. 제 능력으로는 지금과 같이 경험을 공유하는 것이 그나마 최선일 듯 합니다만.. ^^
올해 금융업에 뛰어들어, 오픈소스DBMS 적용을 어찌어찌 하다보니.. 예전에는 별 생각이 없이 넘어가던 가벼운 생각들도, 꽤나 진지한 주제로 제게 다가오네요.
다음 포스팅은 언제일지는 모르지만.. 시간이 될 때.. adt를 주제로 한번 읊어보는 것도 좋겠다는 생각이..
좋은 밤 되시와요~!!