Overview
MySQL 5.6부터는 Online ddl 기능을 제공하기 시작하였지만, 사실은 이전에도 트리거 기반의 online alter 유틸로 서비스 중단없이 테이블 스키마 변경을 수행했었습니다. 이중 percona에서 제공해주는 pt-online-schema-change가 많이들 활용되고 있는데요. 오늘은 돌다리도 망치로 때려가면서 안정성에 신중히 접근한 우리의 케이스에 대해서 데이터 기준으로 얘기를 해보고자 합니다.
pt-online-schema-change?
얘기하기에 앞서서, 이 툴에 대해서 다시한번 짚어보겠습니다. 대충 동작 순서는 아래와 같이..
- 변경할 스키마 구조의 임시 테이블을 생성하고,
- insert/update/delete 트리거를 만들어서 최근 변경 데이터를 동기화하고,
- 처음부터 끝까지 일정 청크 사이즈로 읽으면서 임시 테이블에 복사한 후,
- 완료되면 RENAME TABLE하여 완료
동작합니다.
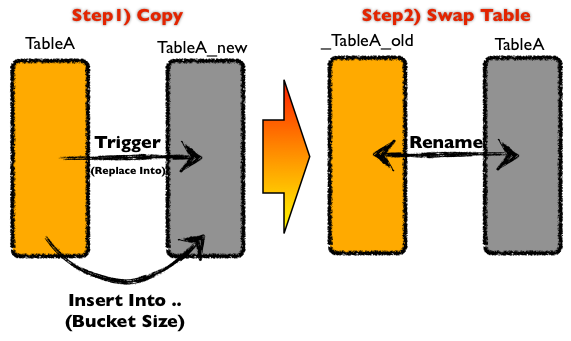
조금더 시각화된 설명을 원한다면. 하단 블로그를 참고하세요.
>> http://small-dbtalk.blogspot.kr/2014/02/mysql-table-schema.html
Goals
24*365 서비스인만큼, 목표는 여전히 명쾌합니다. 심플하쥬?
- 무중단 스키마 변경
- 서비스 영향도 제로
그런데, 구닥다리 MySQL 버전을 사용하지 않으면서, 왜 pt-online-schema-change와 같은 툴 얘기를 꺼내냐고요? 우선은 상황에 따라 가능하지 않기 때문입니다.
>> https://dev.mysql.com/doc/refman/5.6/en/innodb-create-index-overview.html
DML이 블록킹되는 케이스(Permits Concurrent DML이 NO인 경우) 에서는 절대적으로 온라인 서비스 적용이 불가합니다.
혹은 아래와 같이 다수의 alter를 동시에 적용하고자 하는 케이스도 찾아볼 수 있고..
alter table tab
add excol01 varhcar(10),
add excol02 text,
add key ix_col01(col01),
add key ix_excol01(excol01);
로그성 테이블이 일정 사이즈 이상된 시점에 “파티셔닝 적용하는 케이스”도 생각해볼 수 있겠네요.
그렇기에, (개인적인 생각으로는) 아무리 online ddl 기능이 좋아질지라도, pt-online-schema-change와 같은 트리거 기반의 스키마 변경 유틸은 여전히 유효할 것으로 조심스레 예측해봅니다. 적용 여부 판단은 데이터쟁이의 판단 하에..ㅎㅎ
Risk Point
아무튼 지금까지 우리의 상황을 정리해보고자 한다면..
- MySQL의 online ddl 사용 불가
- 서비스 영향도 없은 무중단 스키마 변경
두 가지 상황이고, 이 난관 극복을 위해서 “트리거 기반의 유틸”인 pt-online-schema-change를 활용하기로 하였습니다.
우선 pt-online-schema-change 동작 로직 중, 트리거를 통한 트래픽 발생은 어느정도 예측할 수 있습니다. 타겟 테이블에 발생하는 트랜잭션 양만큼 딱 증가할 것이기에, 현재 데이터 변경량을 보면 어느정도 트랜잭션이 더 늘어날지는 어느정도 판단이 가능하죠.
문제는 처음부터 끝까지 청크 사이즈로 읽어가면서 임시 테이블에 데이터를 복사하는 경우 이 부분인데요. 데이터 복제를 위함이든, 데이터 복구를 위함이든, MySQL에는 바이너리 로그가 거의 필수입니다. 즉, 데이터 복사를 위한 처리 부분도 어떤 방식이든 바이너리 로그에 기록됩니다. 최근에는 바이너리 로그 포멧이 변경된 ROW 자체가 기록이 되는 ROW 포멧 방식으로 대부분 동작합니다. 게다가 만약 트랜잭션 ISOLATION LEVEL을 READ-COMMITTED 사용하고자 한다면, ROW FORMAT이 전제 조건입니다.
여기서 우리의 상황에 세번째 항목을 붙여 아래와 같이 얘기해봅니다.
- MySQL의 online ddl 사용 불가
- 서비스 영향도 없은 무중단 스키마 변경
- 바이너리 로그는 ROW 포멧으로 동작
처음부터 끝까지 데이터를 카피하는 상황에서, 바이너리 로그 사이즈가 기하급수적으로 늘어나는 것에 대한 영향도를 최소화해야 합니다. 대략 다음 두가지 정도?
- 네트워크 트래픽 과도로 인한 서비스 영향 발생 가능
- 바이너리 로그 과다 적재로 인한 디스크 Full 발생 가능
서비스에 직접적인 영향을 미칠 뿐만 아니라, 잘못하면 서비스 불능 상태로까지 이어질 수 있습니다. (특히 2번 케이스는.. 서비스 멈춰요~ ㅜㅜ)
Let’s solve
문제가 있으면 해결하면 되고, 해결할 수 없으면 대안을 마련하면 되고.. 아무튼.. 임팩 최소화 노력을 해보도록 하죠.
1. Reduce Chunk Size
Chunk 단위로 데이터를 카피하는 구조이기 때문에, 다량의 로그가 슬레이브 서버로 스파이크 튀듯이 전송되는 상황은 막아야합니다. 순간순간 바이너리 로그 폭발(?)이 일어나며 서비스 영향을 줄 수 있는 요소가 있습니다.
예를들자면, 1G짜리 테이블 100만건과 20G짜리 100만건 테이블 중, 우리에게 주어진 상황에서 더욱 리스크한 녀석은 누구일까요? -_-; 당연히 20G짜리 테이블입니다.
동일한 ROW 사이즈로 데이터 복사를 해버리면, 매 트랜잭션마다 꽤나 큰 바이너리로그가 한방에 생성됩니다. 특히 semi-sync를 쓰는 경우에는 이 전송에 따른 지연이 기존 트랜잭션에 영향을 줄 수도 있습니다. 그렇다면.. 이런 케이스에서 적용해볼 수 있는 방법은 Chunk Size를 줄여서 이런 리스크 요소를 최소화해보는 것입니다. 잘게잘게 잘라서.. 임팩을 줄여가면서.. 조금씩 조금씩.. (대신 쿼리량은 늘어나게 되버리는.. 쥬릅ㅜㅜ)
pt-online-schema-change 툴에서는 chunk-size 옵션으로 제거 가능하며, 이 값을 기본값(1000)을 적절하게 하향 조정해봅니다. 물론 각 Copy 사이사이마다 일정 시간 쉬어갈 수 있는 interval이 있다면.. 더욱 제어가 쉬웠을텐데. 아쉽게도, 아직은 제공하지 않습니다. (만들어서 percona에 적용해달라고 푸시해볼까요? ㅋㅋ)
아무튼 이렇게해서 만들어진 스크립트 실행 구문은 아래 형태를 보이겠네요.
pt-online-schema-change \
--alter "add excol01 varhcar(10)" D=db1,t=tbname \
--chunk-size=200 \
--defaults-file=/etc/my.cnf \
--host=127.0.0.1 \
--port=3306 \
--user=root \
--ask-pass \
--chunk-index=PRIMARY \
--charset=UTF8 \
--execute
2. Change Session Variables
테이블 사이즈가 너무 커서, 바이너리 로그를 담기에 여의치 않을 때를 생각해봅시다. 물론 미리미리 binlog purge하면서 과거 로그를 제거해볼 수 있겠지만, 사실 백업/복구 입장에서 “데이터 변경 이력 로그” 삭제는 리스크할 수도 있습니다. Point-In Recovery가 안될 수도 있기 때문이죠.
이 경우에서는 데이터 측면에서 조금 다르게 접근해 보자면, 우선 서비스 환경은 아래와 같습니다.
- 현재 트랜잭션 ISOLATION LEVEL은 READ-COMMITTED이다.
- 현재 바이너리 로그는 ROW 포멧이다.
그렇다면.. 데이터를 카피하는 백그라운드 프로세스 기준에서도 위 조건을 충족해야할까요? 데이터 카피시 발생하는 쿼리를 SQL기반의 statement 방식으로 바이너리로그에 기록을 해보면 안될까요?
pt-online-schema-change에서의 세션 파라메터를 아래와 같이 지정을 해본다면,
- COPY 프로세스의 트랜잭션 ISOLATION LEVEL은 REPEATABLE-READ이다.
- COPY 프로세스의 바이너리 로그는 STATEMENT 포멧이다.
상황으로 접근해보면 어떨까요? pt-online-schema-change에서는 세션 파라메터로 set-vars 옵션에 각 파라메터 지적을 콤마로 구분해서 적용해볼 수 있습니다.
pt-online-schema-change \
--alter "add excol01 varhcar(10)" D=db1,t=tbname \
--chunk-size=200 \
--defaults-file=/etc/my.cnf \
--host=127.0.0.1 \
--port=3306 \
--user=root \
--ask-pass \
--chunk-index=PRIMARY \
--charset=UTF8 \
--set-vars="tx_isolation='repeatable-read',binlog_format='statement'" \
--execute
사실 이렇게 수행을 하면, 바이너리 로그 사이즈는 걱정할 필요 없습니다. 게다가 네트워크 트래픽도 거의 차지 않을 것이고. 참으로 안전해보이고, 무조건 이렇게 사용하면 될 것 처럼 생각할 수도 있겠습니다만.. 적어도 이로인한 영향도는 미리 파악하고 사용하는 것이 좋겠죠?
1. isolation level 에 따른 Locking
아무래도 isolation level 이 한단계 높은 수위(read-committed -> repeatable-read)로 관리되다보니, Lock 영향도를 무시할 수 없겠죠? “next key lock“이라든지.. “gap lock“이라든지.. 이런 영향도를 동일하게 받을 수 있다는 점을 인지하고 있어야 합니다. (물론 대용량 테이블에서는 영향도가 제한적이기는 합니다. ㅎㅎ)
2. 슬레이브는 여전히 ROW FORMAT
마스터에서는 STATEMENT FORMAT으로 바이너리로그 기록이 잘 되고는 있습니다만, 문제는 슬레이브에서는 여전히 “ROW FORMAT”으로 기록됩니다. 이건 쿼리 패턴(insert ignore .. select .. )에 따른 어쩔 수 없는 요소로.. 슬레이브는 그냥 주기적으로 purge하면서 대응을 하는 것이 제일 현명해 보이네요. 아.. log-slave-updates 옵션을 ON 상태로 운영하는 경우만 해당되겠네요.
Conclusion
물이 흐르듯 데이터도 흐릅니다. 물길이 변하면 유속이 바뀌듯, 데이터도 마찬가지입니다.
흐름을 “잘 제어하기” 위해 온라인 툴을 활용하였고, 내가 원하는 모양으로 만들기 위해 거쳐갈 “데이터의 흐름“을 생각해보았습니다. 그리고, 발생할 수 있는 “리스크를 예측“해볼 수 있었죠.
예전에는 아무 생각없이 썼던, 손 쉬운 online alter 툴로만 인지를 했었지만.. 서비스가 무시무시하게 사악(?)해지고 나니 돌다리도 쇠망치로 두드려보며 건너보게 되더군요.
사실 이것이 정답은 아닙니다. 더 좋은 방안도 있을 것이고. 효율적인 개선안도 있을 것이고. 그렇지만, 데이터쟁이답게, 닥쳐올 미션들을 “데이터의 흐름”에 촛점을 두어 앞으로도 “장애없는 서비스“를 만들어가도록 노력만큼은 변함이 없을 것입니다. 🙂
좋은 밤 되세요. ㅋ
0 thoughts on “소소한 데이터 이야기 – pt-online-schema-change 편 –”
Comments are closed.