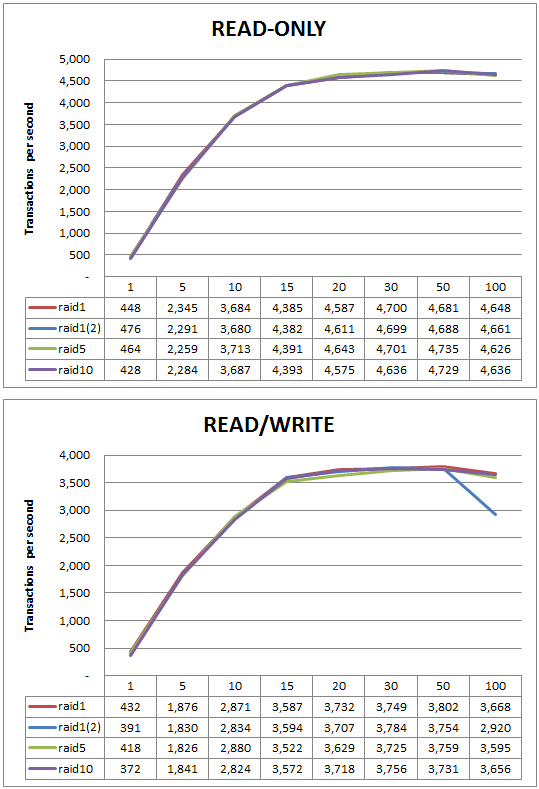
안녕하세요. 오늘 짧지만 재미있는 내용을 하나 공유할까 합니다.
커버링 인덱스(Covering Index)라는 내용인데, 대용량 데이터 처리 시 적절하게 커버링 인덱스를 활용하여 쿼리를 작성하면 성능을 상당 부분 높일 수 있습니다.
커버링 인덱스란?
커버링 인덱스란 원하는 데이터를 인덱스에서만 추출할 수 있는 인덱스를 의미합니다. B-Tree 스캔만으로 원하는 데이터를 가져올 수 있으며, 칼럼을 읽기 위해 굳이 데이터 블록을 보지 않아도 됩니다.
인덱스는 행 전체 크기보다 훨씬 작으며, 인덱스 값에 따라 정렬이 되기 때문에 Sequential Read 접근할 수 있기 때문에, 커버링 인덱스를 사용하면 결과적으로 쿼리 성능을 비약적으로 올릴 수 있습니다.
[Read More]