Overview
바로 이전 하루 2.5억 트윗을 저장하는 트위터의 새로운 저장 스토어 포스팅에서 트위터의 새로운 저장 스토어에 관해서 전반적으로 설명 드렸는데요, 이번에는 그 중 Gizzard에 관해서 심층 분석(?)을 해볼까합니다.
Gizzard는 트위터에서 데이터를 분산 및 복제 관리하기 위한 자체 개발 프레임워크입니다. 클라이언트와 서버 사이에 위치하며 모든 데이터 요청을 처리하는 구조입니다. Gizzard 관련 몇 가지 키워드는 아래와 같습니다.
- 분산 관리(Sharding), 분할(Partitioning), 복제(Replication)
- 부하분산(Load-Balancing)
- 장애복구(Fail-Over)
- 멱등성(idempotent), 가환성(commutative)
- 멱등성 : 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질
- 가환성 : 연산의 순서를 바꾸어도 그 결과가 변하지 않는 일
분산 관리(Sharding)이란?
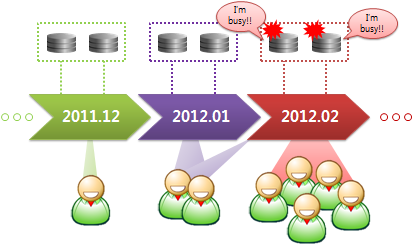
과거에는 서비스 성능 저하가 발생하면 곧바로 해당 서버에 CPU또는 Memory 사이즈를 증설하여 성능 이슈를 해결하였습니다. 하지만, 최근 Web 서비스에서 데이터 사이즈가 급증하여, 더 이상은 서버 성능 고도화만으로는 한계가 있기 때문에, 다수 장비에 데이터를 분산 위치(Data Sharding)하여 데이터를 처리하는 움직임이 일반화되고 있습니다.
[Read More]