Overview
트위터의 새로운 분산 관리 라이브러리 Gizzard를 소개합니다.를 알아보던 당시 부사수 임창선님과 진행했던 또 다른 해외 사례 Tumblr를 정리해보았습니다.
Tumblr는 국내에서는 사용자가 많지는 않지만, Twitter 정도의 트래픽을 자랑하는 Micro Blog 서비스입니다. 하루 평규 5억 이상의 PV가 나오고, 초당 4만 건 이상 Request가 나오며, 하루 평균 3TB 이상의 데이터를 쌓는다고 하니 엄청난 서비스인 것은 틀림 없습니다.
이정도 데이터를 관리하기 위해서 수 천대 이상의 서비스를 운영한다고 하는데, 데이터 관리를 MySQL을 활용하여 제공한다고 합니다. 그렇다면 MySQL로 어떻게 대용량 데이터를 멋지게 다뤘을까요?
Tumblr?
데이터 저장에 사용하고 있는 MySQL머신 수는 약 175대 이상(지금은 더욱 많아졌겠죠^^)이며, Master 데이터 용량만 약 11TB 이상(단일 데이터 건수 250억 건 이상)이라고 합니다. 어마어마한 데이터 용량이죠.
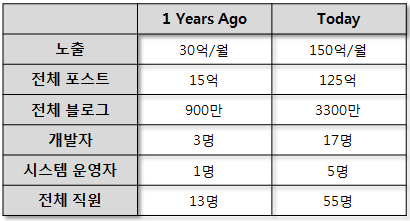
1년 동안 Tumblr 상황을 비교한 표입니다. 엄청난 데이터를 약 20명 정도의 인력으로 관리하고 있다니, 감탄을 금치 않을 수 없네요.^^
(정확히 언제 1년 전/후 인지는 파악은 안됩니다. ㅋ)
Shard Automation
Tumblr에서는 Shard를 자동화 구성을 위해 다음같은 것들을 구현하였습니다.
- 모든 Shard에 관한 위상 정보 수집
- 서버 설정을 조작하기 위한 Unix 명령 및 DB 쿼리 실행
- 여러 서버로 대용량 파일을 복사
- 임의의 데이터셋에 대한 Import/Export
- 단일 Shard를 대중 Shard로 분리할 수 있는 기능
Shard 목표는 다음과 같습니다.
- 지나치게 큰 Shard 조각을 새로운 N개의 Shard로 재배치한다.
- Lock이 없어야하며 어플리케이션 로직도 필요 없어야 한다.
- 5시간 안에 800GB 데이터 파일을 2개로 나누어야 한다.
- 전체적으로 서비스에 전혀 지장이 없어야 한다.
Shard 자동화는 다음 원칙하에 이루어집니다.
- 모든 테이블은 InnoDB Storage Engine을 사용한다.
- 모든 테이블은 Shard Key로 시작하는 Index를 가진다.
- Shard Schema는 Range-based로 한다.
- Shard 과정 중 스키마 변경은 없다
- 디스크 사용률이 2/3 미만이거나, 별도 디스크가 있어야 한다.
- Shard Pool 마다 2 대의 대기 Slave 서버가 존재해야 한다.
- Master와 Slave 사이의 균일한 MySQL 설정 한다.
(log-slave-updates, unique server-id, generic logbin and relay-log names, replication user/grants) - Master Slave 사이에 데이터 동기화에 지연이 있으면 안된다.
- 잘못된 Shard에 일시적인 중복된 행은 서비스에 문제가 안된다.
Shard Process
Shard는 다음과 같은 프로세스 대로 자동화 구현합니다.
- 기존 Shard Pool에서 새로운 Slave N개 생성
- 신규 Slave에 기존 Master 데이터 분할 저장
- READ를 신규 분할 Master(신규 Slave)로 이동
- Write를 신규 분할 Master(신규 Slave)로 이동
- 기존 Master와 신규 Master 서버 간 Replication 끊기
- 신규 Master 데이터 보정
1) 기존 Shard Pool에서 새로운 Slave N개 생성
커다란 데이터 파일을 N개의 Slave 서버로 빠르게 재비치 하는 것을 목표로 합니다.
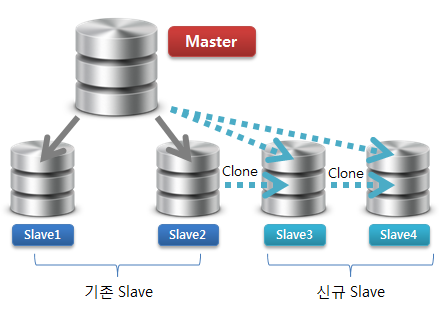
pigz(Parallel gzip)을 사용 빠르게 압축하고, 그와 동시에 유닉스 명령어인 nc로 신규 Slave에 파일을 바로 전송합니다.
Slave4(신규 장비)에 nc로 포트 개방 및 압축 해제하도록 구성합니다.
[mysql@Slave4~]$ nc -l 10000 | pigz -d | tar xvf -
Slave3(신규 장비)에 tee와 fifo를 활용하여 받음과 동시에 데이터를 Slave4로 보내도록 구성합니다.
[mysql@Slave3~]$ mkfifo myfifo
[mysql@Slave3~]$ nc Slave4 1234 <myfifo &
[mysql@Slave3~]$ nc -l 10000 | tee myfifo | pigz -d | tar xvf -
Slave2(기존 장비)에서 압축 후 nc 로 바로 신규 데이터를 전송하도록 합니다.
[mysql@Slave2~]$ tar cv ./* | pigz | nc Slave3 10000
Slave2 -> Slave3 -> Slave4 로 동시에 순차적으로 데이터가 전송됩니다. 결과적으로 세 대 Slave 장비는 CPU, Memory, Disk, Network 등을 효율적으로 사용하게 되죠.^^ 순차적으로 복사하거나 단일 소스에서 병렬로 복사하는 것보다 훨씬 성능이 좋습니다.
위 그림처럼 텀블러가 Slave 장비를 서비스에 투입하지 않고 Standby 상태로 구성하는 이유는 pigz의 사용시 발생되는 리소스 부하로 인한 서비스의 영향도 때문으로 추측됩니다. 실제 테스트를 해보니 서버 리소스 영향이 있었습니다.
17:16:54 CPU %user %nice %system %iowait %idle
17:16:55 all 53.80 0.00 3.55 3.05 39.60
17:16:56 all 67.00 0.00 4.25 2.38 26.38
17:16:57 all 40.11 0.00 2.68 5.24 51.97
17:16:58 all 70.75 0.00 4.36 2.12 22.78
17:16:59 all 63.27 0.00 3.81 3.69 29.23
17:17:00 all 64.57 0.00 4.30 2.06 29.07
17:17:01 all 51.00 0.00 3.62 4.50 40.88
17:17:02 all 57.96 0.00 4.37 2.87 34.79
2) 신규 Slave에 기존 Master 데이터 분할 저장
신규 Slave에 기존 데이터를 N개로 나눠서 저장합니다.
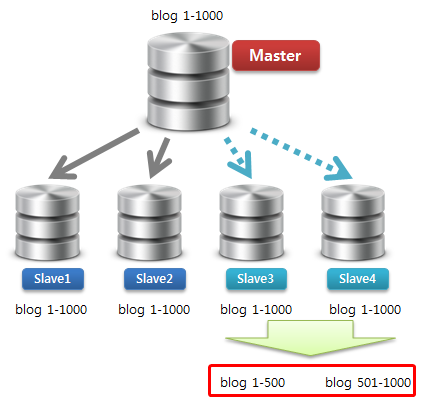
그런데 데이터를 분할하는 방식이 참으로 재미 있습니다.
먼저 Select .. Into Outfile로 데이터를 추출하고, 테이블을 Drop 및 Create 한 후 추출한 데이터를 Load Data Infile로 다시 넣는 것입니다.
과연 무엇이 더 빠른 것인지 판단이 정확하게 서지는 않지만, Tumblr에서는 기존 데이터를 날리고 Bulk Insert 하는 것이 훨씬 빠르다고 판단한 것 같습니다.
Load Data가 정상적으로 마무리되면, 신규 Slave 밑에 각각 두 개 Slave를 붙입니다. 아래 그림과 같은 형상이 되겠죠.^^
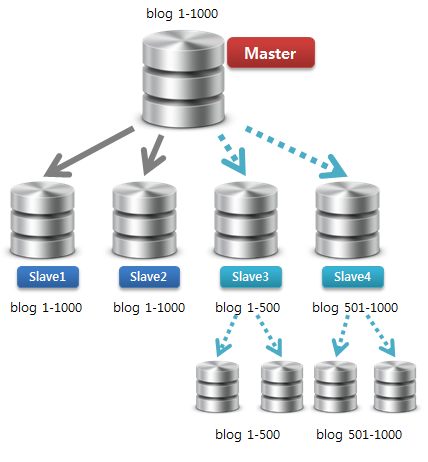
아래는 데이터를 Export/Import 시 주의할 사항이라고 합니다.
- import 속도를 위해 바이너리 로그를 비활성화 한다.
- 쿼리를 Kill하는 스크립트는 사용하지 않는다.
(SELECT INTO OUTFILE과LOAD DATA INFILE는 KILL하지 않도록 함) - 어느 정도 import/export가 가능하지를 벤치마크하여 파악한다.
- 속도가 다른 디스크 여러 개를 동시 사용하는 경우 디스크 I/O 스케줄러 선택을 주의한다.
한 가지 의문이 가는 사항은 정상적인 Replication 상태라면 분명 신규 Slave에서 Replication Fail이 발생했을 것 같다는 것입니다. 아무래도 Slave 서버에서 모든 Error를 무시하는 설정을 해놨다는 생각이 드네요.
또한 Binlog Log 는 아무래도 Row 포멧이 위와 같은 경우에서는 조금 더 유리하지 않을까요? 그냥 추측 두 가지를 해봅니다.^^
3) READ를 신규 분할 Master(신규 Slave)로 이동
어플리케이션에서 READ를 기존 Master에서 신규 Slave(앞으로 Master로 구성될 서버)로 이동을 하여 서비스를 진행합니다.
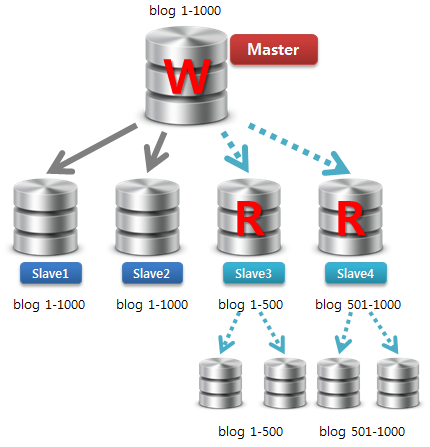
만약 어플리케이션 서버에서 업데이트가 동시에 완료되지 않은 상태에서 갑자기 Read/Write 포인트가 이동한다면, 데이터 일관성 문제가 발생할 것입니다.
동시에 Write까지 이동되었다고 가정해봅시다. A가 새로운 DB 형상을 받고 200 게시물을 작성하였으나, B는 여전히 예전 형상을 바라보고 기존 Master 서버에서 데이터를 읽어오면 게시물을 찾을 수 없겠죠.
그렇기 때문에 기존 Master와 데이터 복제를 유지하면서 Read 포인트만 먼저 이동하는 것입니다.
4) Write를 신규 분할 Master(신규 Slave)로 이동
모든 DB 구성에 관한 형상이 업데이트 된 후에 Write 포인트를 변경합니다. 옮긴 후에도 기존 Master DB의 바이너리 로그 기록이 정지하기 전까지는 절대 기존 Master/Slave 구성에 손을 대면 안되겠죠.^^
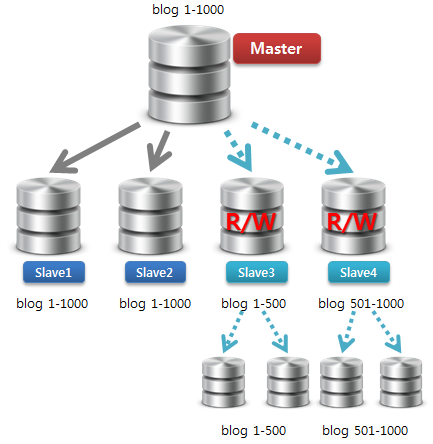
5) 기존 Master와 신규 Master 서버 간 Replication 끊기
기존 Master의 바이너리 로그 기록이 중지되었다면, 이제 필요없는 DB들을 제거하도록 합니다.
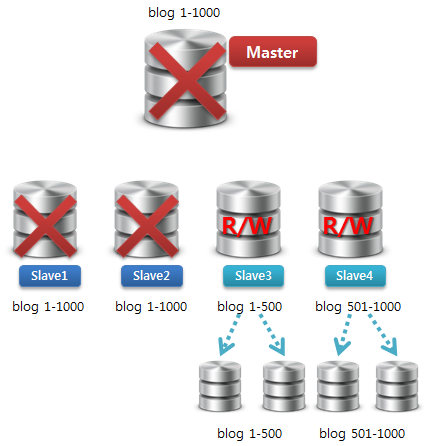
이제 모든 데이터는 새로운 Slave 아니 새로운 Master에서 Read/Write 서비스되겠죠. ^^
6) 신규 Master 데이터 보정
분할된 Shard된 조각에서 잘못 복제된 데이터를 제거하는 작업이 필요합니다.
그러나 절대적으로 하나의 커다란 단위의 Delete 작업은 피하도록 합니다. Master/Slave 간 데이터 동기화 지연을 최소화하기 위한 방안이죠.
그러므로 Delete 작업도 조금씩 끊어서 수행하도록 유도합니다.
Conclusion
정리를 하자면, 서비스에 투입하지 않은 Slave에서 빠르게 복제 서버를 두 대 추가하고, Master 데이터를 각각 반으로 나눠서 분리 저장한다 고 보면 되겠습니다. Tumblr에서는 내부적으로 조금더 상세한 내용을 공유하지 않았지만, 적어도 데이터를 Shard하는 동안에는 서비스 Downtime이 없다는 것입니다.
Scale-Out 방안이 다양하지 않은 MySQL에서 이러한 방식으로 신속하게 Scale Out할 수 있었던 기법에서 많은 점을 배운 것 같네요.^^
대용량 데이터 관리를 위한 어플리케이션 개발도 필요하겠지만, 전체적인 데이터 흐름을 아는 것이 무엇보다 중요하다고 생각합니다.
<참고 사이트>
- Massively Sharded MySQL
- Efficiently copying files to multiple destinations
- Tumblr Architecture - 15 Billion Page Views A Month And Harder To Scale Than Twitter