Overview
**Amazon Relational Database Service(Amazon RDS)**는 클라우드에서 관계형 데이터베이스를 쉽게 설치, 운영 및 확장할 수 있는 서비스입니다.
자원을 유연하게 배분할 수 있는 이점이 있는 클라우드이지만, 모든 서비스는 결국에는 사람 손을 거쳐야 하고, 때로는 인재로 인한 데이터 유실 사고가 발생할 수 있습니다.
사용이 편리하게 구현되어 있지만, 사용자에게 제공하는 권한 또한 상당히 제약적(인스턴스 관리자일지라도)입니다.
오늘은 Amazon RDS 상에서 데이터 유실 장애가 발생한 경우 대처할 수 있는 방안에 관하여 포스팅하도록 하겠습니다. (기준은 MySQL이나 타 DBMS도 큰 차이가 없을 것 같네요^^)
복구 순서는 다음과 같습니다.
- 백업 DB 인스턴스 생성
- 임시 복구 테이블 생성
- 데이터 추출 및 복원
백업 DB 인스턴스 생성
Amazon RDS에서는 앞서 언급드린 것과 같이 사용자에게 제공하는 권한이 상당히 제약적입니다. 무엇보다 DB서버에는 OS개념이 없고, 오직 DBMS에 개방된 포트를 통해서만 DB 접속이 가능합니다. 그리고 사용 시 불필요한 권한 또한 대부분 회수 되어 있죠. 결과적으로 로컬 IDC에서 데이터 유실 발생 시 Binlog Position을 활용하여 장애 시점 이전으로 데이터를 돌리는 것이 불가합니다.
하지만 RDS에서는 Restore To Point In Time 라는 기능을 제공합니다. 새벽에 생성된 DB 이미지와 내부적으로 Binary Log를 취합하여 실제 사용자가 원하는 시점의 DB 인스턴스를 생성하는 기능이죠.
백문이불여일견!! 한번 보시죠^^
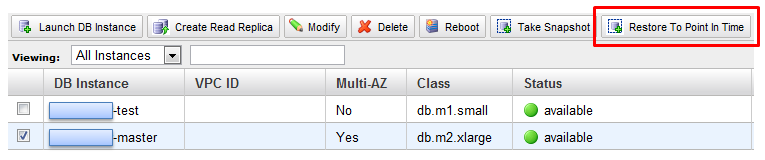
Amazon RDS 콘솔 상에서 Restore To Point In Time버튼을 클릭합니다. 그러면 하단과 같이 DB 인스턴스 생성을 위한 옵션을 입력하는 레이어가 뜹니다.
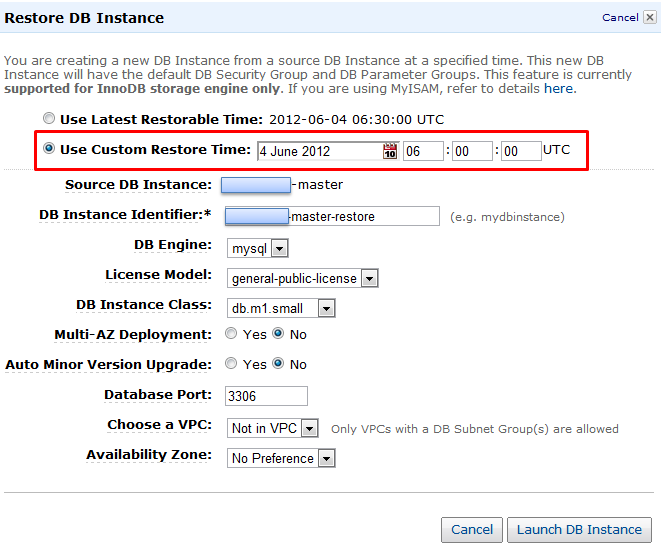
Restore Time을 장애 시점 이전으로 설정합니다. 물론 장애 시점과 가까울수록 데이터 신뢰성을 더욱 커지겠죠. 단, 여기서 시간은 UTC 기준으로 넣으셔야 합니다.
DB Instance Identifier에는 생성할 DB 인스턴스 이름이니, 기존 네이밍과 중복이 되지 않도록 지정합니다.
기타 옵션은 큰 의미는 없으나, 비용적인 측면을 고려하여 DB Instance Class를 Small 사이즈로 설정합니다. (생성된 DB에서는 단순 Data Export만 수행할 것이기 때문에 좋은 성능은 필요 없습니다.)
옵션을 모두 입력을 하고 Launch DB Instance를 클릭하면 아래와 같이 새로운 DB 인스턴스가 생성이 됩니다. ^^

DB 인스턴스가 생성되는 과정은 기존 운영되고 있는 서비스 DB에는 영향을 주지 않습니다. 새벽에 스냅샷 형태로 풀 백업된 DB 이미지에 Binary Log 변경 사항을 내부적으로 취합하기 때문이죠. ^^
오~랜 시간이 지난 후 확인을 해보면 백업 DB 인스턴스 Status가 Available로.. 즉 새로운 DB 인스턴스 생성이 완료되었습니다 . 참 쉽죠??
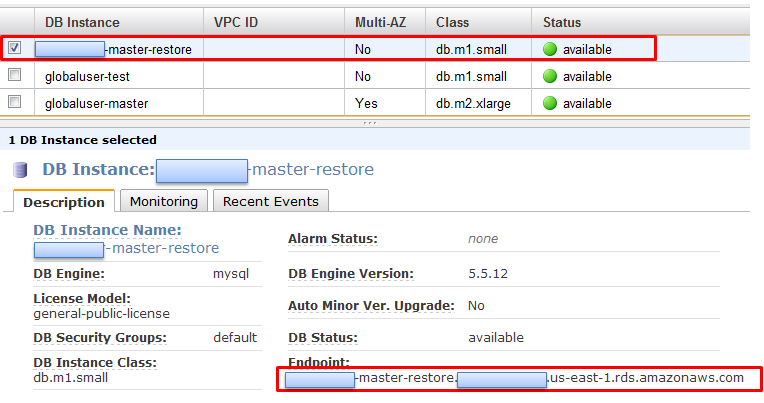
신규로 생성된 백업 DB 인스턴스를 클릭하면 관련 Description이 위와 같이 나오는데, 여기서 End Point를 보면 RDS에 접근하기 위한 주소가 나옵니다. 클라이언트에서는 End Point를 통해서 DB 접속을 진행하면 됩니다.
임시 복구 테이블 생성
자! 이제 백업 DB 인스턴스를 생성하였으니, 데이터를 복구하는 단계로 넘어가야겠죠? 사전에 복구할 테이블과 동일한 구조의 테이블을 생성을 합니다. 데이터 이관을 Export/Import로 데이터를 이관하기 위함입니다.
임시 복구 테이블 생성
mysql> create table tb_repair_tmp like tb_repair;
Query OK, 0 rows affected (0.42 sec)
인덱스 제거
임시 테이블을 Rename할 목적이 아니라면, 기존 인덱스는 필요하지 않습니다. 과감하게 날려줍니다!! Primary Key는 물론 제외하고 날리셔야겠죠? ^^;;
mysql> drop index idx_tb_repair_indt on tb_repair_tmp;
Query OK, 0 rows affected (0.30 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> drop index idx_tb_repair_closedt on tb_repair_tmp;
Query OK, 0 rows affected (0.31 sec)
Records: 0 Duplicates: 0 Warnings: 0
복원을 위해 데이터를 저장할 임시 테이블까지 모두 생성하였습니다.
데이터 추출 및 복원
mysqldump 유틸리티를 활용하여 데이터를 dump하는 동시에 sed유틸리티로 테이블명만 임시 백업 테이블명으로 변경하여 바로 데이터를 입력합니다.
MySQL에서 테이블 스키마를 “무중단”으로 변경해보자!! 편에서 데이터를 이관한 것과 동일한 방식입니다. ^^ 얼마전 RDS 데이터 복원을 하며 대충 만들어놓은 스크립트를 우연찮게 재사용하게 되었네요. ㅎㅎ
명시적인 명령어는 하단과 같습니다.
$ mysqldump -udbuser -pxxxxx \
--single-transaction \
--no-create-db \
--no-create-info \
--triggers=false \
--comments=false \
--add-locks=false \
--disable-keys=false \
--host=xx-master-restore.xx.us-east-1.rds.amazonaws.com \
--port=3306 \
--databases targetdb \
--tables tb_repair \
| sed -r 's/^INSERT INTO `tb_repair`/INSERT INTO `tb_repair_tmp`/gi' \
| mysql -udbuser -pxxxxx \
--host xx-master.xx.us-east-1.rds.amazonaws.com \
--port 3306 targetdb
mysqldump에 들어가는 host는 백업 DB 인스턴스 End Point이고, mysql에 들어가는 host는 복원할 서버 End Point입니다. 헷갈리면 안됩니다!!
위 작업이 마무리되면 임시 테이블에 장애 시점 이전의 데이터가 들어있는 것을 확인할 수 있습니다.
데이터 보정
장애 시점 이전 데이터를 구성하였으니, 이제는 구성된 데이터를 활용하여 전체적인 데이터 복구 작업을 마무리합니다. 장애를 유발한 SQL에 따라서 복구 시나리오가 다릅니다.
Case 1 : Drop Table
단순하게 테이블 Rename합니다. 물론 Rename을 하기 위해서는 앞서 진행했던 인덱스 제거 작업을 해서는 안되겠죠.
Case 2 : Delete Table (Truncate Table)
테이블에 데이터는 없으나, 지속적으로 누적되고 있는 경우입니다. 이 경우는 누적되는 데이터를 선별해서 데이터를 복원해야 합니다.
하단과 같이 임시 테이블에는 존재하나 원본 테이블에는 없는 데이터를 선별해서 데이터를 복원합니다. DB에 무리가 가지 않도록 10만 건씩 나눠서 데이터를 복사합니다. 여기서 seq는 각 테이블의 Primary Key입니다.
insert into tb_repair
select a.*
from tb_repair_tmp a
left join tb_repair b on a.seq = b.seq
where b.seq is null
limit 100000;
Case 3 : Update Table
다음과 같이 update 시 inner join을 수행하여 데이터를 보정합니다. DB에 무리가 가지 않도록 10만 건씩 나눠서 데이터를 업데이트 합니다. 하단은 Primary Key가 Auto_Increment 옵션이 적용된 경우이고, 일반 스트링인 경우에는 limit을 활용하여 적절하게 자르시기 바랍니다.^^ 실수로 특정 필드를 공백으로 업데이트한 경우입니다.
update tb_repair a
inner join tb_repair_tmp b on a.seq = b.seq
set a.passwd = b.passwd
where a.passwd = ''
and a.seq between 1 and 100000;
Conclusion
Amazon RDS에서 제공하는 Restore To Point In Time 기능을 사용하면, DB 장애 처리 시 사용하던 복잡한 Dump 명령 없이 간단하게 데이터를 복원할 수 있습니다.
단, Restore To Point In Time 사용 시 Binary Log 포지션을 일일이 확인하며 장애 시점 바로 이전까지는 복원이 불가하다는 것을 반드시 인지하시기 바랍니다.
그리고 데이터 보정 후 반드시 검증도 꼭 하시고, 기타 웹로그가 있는 경우에도 충분히 반영을 하셔야 합니다.
데이터를 복구한 이후에는 임시로 생성한 DB 인스턴스는 반드시 제거하세요. (비용이 나갑니다.)