Overview
트위터에서 우연히 성능 관련 가벼운 아는척(?)을 시작으로 일이 커지고 말았네요. ^^;; 성능 관련된 트윗을 보고 몇 가지 코멘트만 한다는 것이.. ㅎㄷㄷ한 멘션이 되고 말았습니다.
그래서 부족하나마, MySQL 성능 최적화 시 본능적으로 이행하는 몇 가지를 정리해보겠습니다.
Global Variable
성능과 연관이 되는 몇 가지 파라메터 변수는 반드시 체크를 하시기 바랍니다. MySQL에서 주로 InnoDB를 사용하는 상태라면 innodb_buffer_pool_size, innodb_log_file_size, innodb_log_files_in_group, innodb_flush_log_at_trx_commit, innodb_doublewrite, sync_binlog 정도가 성능에 직접적인 영향을 미치는 요소라고 볼 수 있습니다.
- innodb_buffer_pool_size
InnoDB에게 할당하는 버퍼 사이즈로 50~60%가 적당하며, 지나치게 많이 할당하면 Swap이 발생할 수 있습니다. - innodb_log_file_size
트랜잭션 로그를 기록하는 파일 사이즈이며, 128MB ~ 256MB가 적당합니다. - innodb_log_files_in_group
트랜잭션 로그 파일 개수로 3개로 설정합니다. - innodb_flush_log_at_trx_commit
서비스 정책에 따라 다르게 설정하겠지만, 저는 일반적으로 2값으로 세팅합니다.- 0: 초당 1회씩 트랜잭션 로그 파일(innodb_log_file)에 기록
- 1: 트랜잭션 커밋 시 로그 파일과 데이터 파일에 기록
- 2: 트랜잭션 커밋 시 로그 파일에만 기록, 매초 데이터 파일에 기록
- innodb_doublewrite
이중으로 쓰기 버퍼를 사용하는지 여부를 설정하는 변수로 활성화 시 innodb_doublewrite 공간에 기록 후 데이터 저장합니다. 저는 활성화합니다. - sync_binlog
트랜잭션 커밋 시 바이너리 로그에 기록할 것인지에 관한 설정이며, 저는 비활성 처리합니다.
참고로 innodb_buffer_pool_size를 32G 메모리 서버에서 24G로 할당한 적이 있는데, SQL트래픽이 많아짐에 따라 Swap이 발생하더군요. 버퍼풀에는 대략 한 시간 정도 Active한 데이터와 인덱스를 담을 수 있는 사이징이라면 적절할 것 같습니다.
sync_binlog는 binlog 파일에 매 트랜잭션마다 기록할 것인지를 설정하는 파라메터인데, BBWC 혹은 FBWC이 없다면 활성화를 권고하지 않습니다. (개인적으로 경험해본 바에 따르면 on/off에 따라서 10~20배 정도 차이가 나기도 하더군요.)
Session Variables
MySQL은 단일 쓰레드에서 Nested Loop 방식으로 데이터를 처리합니다. 물론 5.6 버전부터는 조인 알고리즘이 몇가지 더 추가되기는 하지만, 여전히 미흡하죠. 결국 SQL처리 시 일시적으로 사용하는 Temporary Table이 디스크에 사용되지 않도록 유도하는 것이 제일 중요한 것 같습니다.
먼저 mysqladmin 유틸리티로 현재 Temporary Table 현황을 모니터링 하도록 합니다. 매 초마다 Status 차이를 보여주는 명령어이며, Created_tmp_files 이 꾸준히 많다면 tmp_table_size를 늘려줄 필요가 있습니다. Global Variable 에 설정하는 것보다는 필요 시 Session Variable로 설정하는 것을 권고 드립니다.
mysqladmin -uroot -p extended-status -r -i 1 | grep -E 'Created_tmp|--'
통계성 쿼리 질의 전 아래와 같이 세션 변수 설정(2G로 할당)을 한 후 진행하면 한결 빠르게 쿼리가 처리됩니다.
set session tmp_table_size = 2 * 1024 * 1024 * 1024;
set session max_heap_table_size = 2 * 1024 * 1024 * 1024;
하지만 이것은 어디까지나 디스크 접근을 줄이기 위한 목적이므로, 쿼리 자체를 수정하거나 다른 접근 방법으로 데이터를 처리하는 것이 가장 확실한 방법일 것입니다.
만약 Create Table As Select 혹은 Insert into .. Select 구문을 자주 사용하여 통계 데이터를 입력한다면 Transaction Isolation을 READ-COMMITTED로 변경하시기 바랍니다. 구문 실행 도중 Lock이 발생할 수 있기 때문이죠. ^^
예전에 포스팅한 MySQL 트랜잭션 Isolation Level로 인한 장애 사전 예방 법을 참고하세요.
Schema & SQL
MySQL에서는 서버 변수보다는 Schema와 SQL 특성에 큰 영향을 받는 DBMS 입니다. 일단 서버 설정이 기본적인 사이징정도로만 구성되면, 그 이후로는 Schema와 SQL이 DB특성에 맞게 작성되었는지 여부가 성능에 가장 큰 요소가 됩니다.
MySQL 특징은 예전 포스팅 반드시 알아야할 MySQL 특징 세 가지을 참고하시면 되겠습니다.
1) Schema
InnoDB를 주로 사용한다는 가정 하에 말씀 드리겠습니다.
InnoDB 는 Primary Key 순으로 데이터가 저장됩니다. Primary Key가 Rowid처럼 사용되는 것이죠. 만약 Primary Key가 무작위로 입력되는 테이블이라면, 테이블에 데이터가 누적됨에 따라 성능도 비례하게 떨어지게 됩니다. Primary Key는 순차적으로 저장되도록 하며, 만약 구조 상 여의치 않다면 테이블 파티셔닝을 통해서 데이터 파일 사이즈를 최소로 유지하시기 바랍니다.
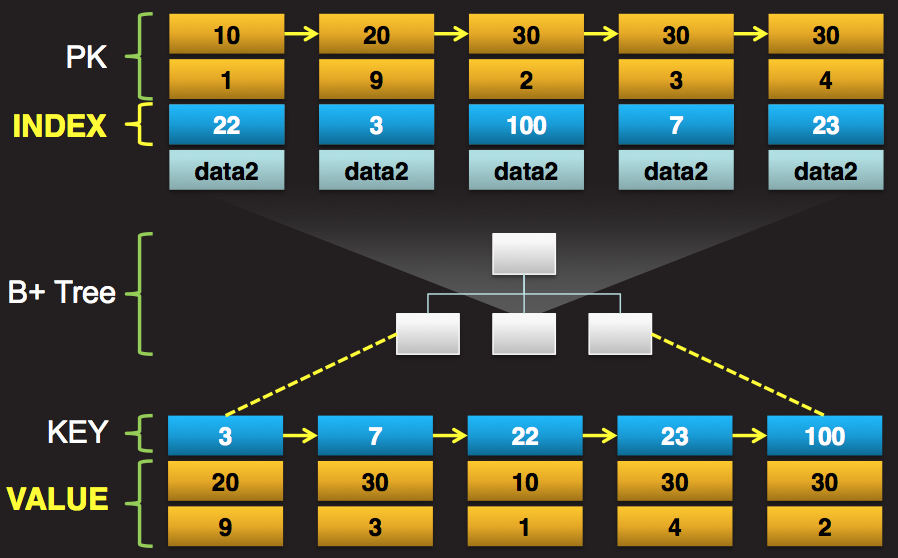
그리고 Secondary Index는 위 그림처럼 Primary Key를 Value 로 가집니다. 모든 Secondary Index 에는 Primary Key를 가지기 때문에 Primary Key의 데이터 타입이 전체 인덱스 사이즈에 큰 영향을 미칩니다.
InnoDB에서는 경우에 따라서, 인덱스가 실 데이터보다 더 큰 경우가 자주 있습니다. 그러한 경우가 있는지를 확인하고, 인덱스 사이즈를 최대한 줄이는 것이 성능상 좋습니다. 간단한 테이블 조회 쿼리입니다.
SELECT
CONCAT(TABLE_SCHEMA,'.',TABLE_NAME) TABLE_NAME,
CONCAT(ROUND(TABLE_ROWS/1000000,2),'M') ROWS,
CONCAT(ROUND(DATA_LENGTH/(1024*1024),2),'M') DATA,
CONCAT(ROUND(INDEX_LENGTH/(1024*1024),2),'M') IDX,
CONCAT(ROUND((DATA_LENGTH+INDEX_LENGTH)/(1024*1024),2),'M') TOTAL_SIZE,
ROUND(INDEX_LENGTH/DATA_LENGTH,2) IDXFRAC,
ENGINE
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA NOT IN ('mysql','information_schema', 'performance_schema')
ORDER BY DATA_LENGTH+INDEX_LENGTH DESC;
문자열 인덱스라면 Trigger + CRC32로 사이즈를 줄일 수 있습니다. 트리거에서 Insert혹은 Update가 발생하면 CRC32 함수로 문자열을 Unsigned Int 타입으로 변환하여 특정 칼럼에 저장하고, 해당 칼럼을 인덱스 필드로 사용하는 것입니다.
간단한 트리거 예제입니다. Insert 관련이며, Update 는 비슷하게 정의하시면 되겠죠. ^^
CREATE TRIGGER trg_test_insert
BEFORE INSERT ON test
FOR EACH ROW
BEGIN
SET NEW.str_crc = CRC32(LOWER(TRIM(NEW.str)));
END$$
질의는 다음과 같이 합니다. 대략 1/43억 확률로 중복 데이터가 발생할 수 있으나, str값을 다시 조회 조건으로 주기 때문에 정상적인 데이터만 가져옵니다.
SELECT * FROM test
WHERE str = 'abcdefg'
AND str_crc = CRC32(LOWER(TRIM('abcdefg')));
이같이 쓰는 이유는 문자열 칼럼에 인덱스를 제거하기 위함이니 헷갈리시면 안됩니다!!
트리거 활용을 잘 하면 DB 자원을 많이 잡아먹는 성능 취약 요소를 최소화할 수 있습니다. 예를 들어 특정 통계 데이터가 자주 필요한 경우라면, 매번 Group By 질의를 하지 않고 트리거로 통계 테이블에 데이터를 적용하면서 수행하는 것도 한가지 방안입니다. 그렇다고 무조건 트리거를 맹신해서는 안됩니다. ^^;; 트리거는 최대한 단순하게 필요한 만큼만!!
2) SQL
SQL 관련은 문제 발생 요소가 너무도 다양해서 자세하게 설명하기가 어렵습니다. 먼저 예전 포스팅 MySQL 성능 죽이는 잘못된 쿼리 습관를 참고하세요.
추가로 몇 가지 설명 더 드리겠습니다. 일단 다음과 같은 쿼리 습관은 좋지 않습니다.
SELECT * FROM userinfo
WHERE id IN (SELECT id FROM userinfo_log
WHERE reg_date > '2012-09-09');
서브 쿼리 실행 후 WHERE 조건을 수행하는 것이 아닌, 매번 데이터를 Nested Loop 탐색을 하면서 서브쿼리를 수행하기 때문에 불필요한 부하가 발생합니다.예전 포스트 Maria 1탄 – MySQL의 쌍둥이 형제 MariaDB를 소개합니다.에 관련된 내용이 있으니 한번 읽어보세요. ^^
또한 다음과 같은 쿼리 습관은 최대한 피하시기 바랍니다.
SELECT ..
FROM (
SELECT .. FROM .. WHERE ..
) a
INNER JOIN (
SELECT .. FROM .. WHERE ..
) b ON a.col = b.col;
두 개의 서브 쿼리가 Temporary Table로 내부적으로 처리되면서, 두 테이블 간 풀 스캔이 발생합니다. Nested Loop방식으로 발생하는 풀 스캔은 시스템 성능에 엄청난 타격을 주므로, 테이블 구조를 잘 파악해서 인덱스를 잘 활용할 수 있도록 쿼리를 이쁘게(?) 작성하세요. (중간 테이블이 1만건씩이면 두 개 테이블 연산에는 1억 번의 연산이 필요합니다. ㅎㄷㄷ;;)
불필요한 Left조인이 있는지, 혹은 지나치게 서브 쿼리를 사용하는지, Select 조건에 들어간 칼럼이 반드시 필요한 데이터들인지, 커버링 인덱스를 사용할 수 있는 지 등여러 가지가 있겠습니다만, 다 언급하기에는 한계가 있네요. ^^
한가지 기억하실 것은 MySQL은 단일 쓰레드에서 Nested Loop 방식으로 데이터를 처리하므로, DB 가 처리할 데이터를 최소화 유도해야 한다는 것입니다.
Conclusion
계획없이 작성한 포스팅인만큼 여기저기 부족하고 보완해야할 부분이 여기저기 많습니다. 그치만 MySQL DB 성능을 최적화한다면, 살펴봐야할 몇 가지라는 생각이 들어서 간단하게나마 정리하였습니다. 성능에 직접적인 영향을 주는 환경 변수만 정책에 맞게 설정을 한 후에는 테이블 구조와 SQL을 MySQL 특성에 맞게 작성을 한다면 가시적인 효과를 빠르게 볼 수 있을 것 같네요. ^^
감사합니다.