Overview
벌써 새해가 밝았네요. 새해 복 많이 받고 계시쥬?
판교 생활을 한지도 벌써 만 7년을 훌쩍 지나, 8년을 향해 가고 있군요. 2020년 우주의 원더키디(아재 인증)의 그 시간이 이렇게나 빠르게 찾아올 줄은 그때의 저는 몰랐답니다. ㅠㅠ
오늘 주제는, 그동안 MySQL innodb memcached 플러그인의 마지막편, (지극히 개인적인 의견인) 서비스적인 활용 편입니다. 상상의 날개를 펼쳐서, 서비스 최우선적인 활용을 위해 무엇을 꿈꿔볼 수 있을지, 이야기 해보고자 합니다. (이전 포스팅은 하단을 참고요.)
1탄. MySQL InnoDB의 메모리 캐시 서버로 변신! – 설정편 –
2탄. MySQL InnoDB의 메모리 캐시 서버로 변신! – 모니터링편 –
두 시리즈에 이은 마지막 활용편 시작합니다.
InnoDB memcached strength
제 기준으로 가장 매혹적인 부분은 memcached protocal로 데이터를 빠르게 접근을 하면서도, 데이터 자체가 디스크에 존재한다는 것입니다. 즉, 휘발성이 아닌 데이터 특성은 굉장히 매혹적이죠.
일반적으로 캐시 시스템에서는 **유한한 메모리 리소스를 효율적으로 활용하기 위해 보통은 TTL(캐시에서 살아있을 수 있는 시간)**을 둡니다. 캐시 데이터가 언제까지 유효한지를 지정을 하고, 해당 시간이 지나버리면, 가차없이 메모리에서 날려버리는 것인데.
만약 TTL을 무한하게 제공을 해볼 수 있다면 어떨까요?
예를 들어, 어플리케이션의 Token 정보라든지, 쉽게 변하지 않을 사용자 정보라든지, 혹은 컨텐츠 정보성 데이터라든지.. TTL을 길게 가져갈 수록 좋을만한 서비스에 적용을 해본다면 어떻까 생각해볼 수 있겠죠. 일반적으로 트래픽이 많이 몰리던 상황(서비스에 따라 다르겠지만)은, TTL이 24시간을 넘지 못해서, 다음날 비슷한 시간대의 트래픽이 상당히 몰릴 때 였던 것 같습니다.
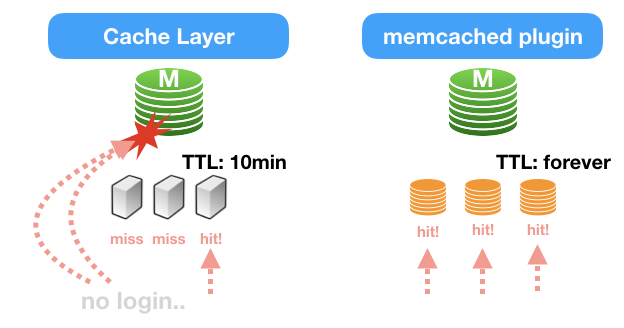
이런 서비스에 조금 전 언급한대로, TTL이 없는 형태로 memcache 프로토콜로 데이터를 접근해볼 수 있다면?? 개인적인 생각으로는 엄청난 효율을 발휘해볼 수 있다고 봅니다. ㅎㅎ
Beyond physical memory
메모리/디스크도 아무래도 제한된 리소스이기 때문에. TTL을 무한히 가져갈 수는 없습니다. TTL을 늘리려면 아무래도, 물리 머신의 디스크와 메모리를 점유해야 하기 때문이죠. 자, 그렇다면, 아래 그림처럼 동일한 데이터를 용도에 따라 영역을 다르게 접근해볼 수 있다면? (각 노드는 리플리케이션 복제본)
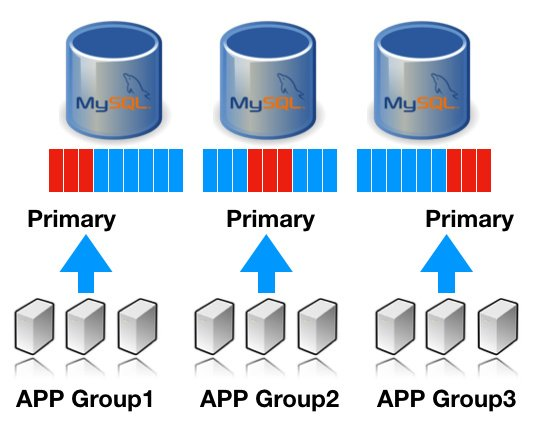 동일한 데이터이지만, 어플리케이션에서 그룹핑해서 영역을 나눠서 본다면, 각 노드 안의 메모리 버퍼풀에 존재하는 데이터는 각각 다를것이고, 결과적으로 가장 효율적인 퍼포먼스를 보여줄 수 있습니다. (동일한 데이터 찢어서 처리하기)
동일한 데이터이지만, 어플리케이션에서 그룹핑해서 영역을 나눠서 본다면, 각 노드 안의 메모리 버퍼풀에 존재하는 데이터는 각각 다를것이고, 결과적으로 가장 효율적인 퍼포먼스를 보여줄 수 있습니다. (동일한 데이터 찢어서 처리하기)
심지어, 특정 노드에서 장애가 발생해서 다른 노드로 역할을 넘겼을 시에도 데이터 일관성에 대해서 걱정할 필요는 없겠죠. ㅎ 모든 노드가 동일한 데이터를 가졌을테니요.
여기에 추가로 발상을 한번더 살짜쿵 전환을 해서. 데이터 복제 측면으로 접근을 해봅시다. 개인적인 생각이지만, MySQL의 강점은 바로 데이터 복제입니다. 그리고 다양한 스토리지 엔진에 효과적으로 데이터 복제를 가능하게 해주는 Binary Log 이야말로, MySQL이 가진 최고의 매력포인트라고 저는 생각을 합니다.
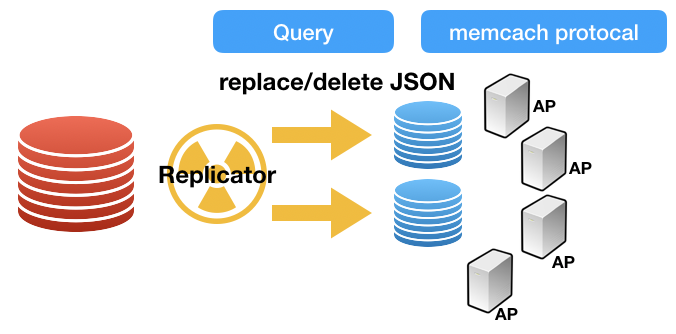
데이터를 MySQL Replication을 통해서 동기화하는 방법도 있지만, MySQL memcached 테이블에 JSON 형태로 직접 넣고, 이것을 memcache plugin으로 꺼내쓰는 것도 좋은 활용도일 것 같네요. ^^
Conclusion
지금까지 총 3번에 걸쳐서 MySQL memcached plugin에 대해서 살펴보았습니다. 1탄에서는 설정 및 퍼포먼스, 2탄에서는 모니터링, 그리고 마지막으로 3탄에서는 뜬그룹 잡는 활용편으로 주제를 잡았었는데요.
마지막 3탄인 오늘 이야기하고 싶은내용은 이렇습니다.
서비스 특성에 따라 다르지만, 적어도 TTL을 최대한 늘릴 수록 효율적인 서비스에서는 최고의 퍼포먼스를 발휘해볼 수 있다라는 이야기를 전하고 싶습니다. 그리고, 캐시 데이터 실시간 적용에는 MySQL Replication을 활용하거나, 혹은 별도의 Binlog 기반의 리플리케이터를 하나 생성해보는 것도 좋은 활용도일 것이고요.
다음 주제로는, 정말 심플하게 접근해볼 수 있는 MySQL Binlog Parser를 이야기해보도 좋을 듯 합니다. ^^
새해 첫 주, 알찬 한주가 되기를 바라면서, 오늘 제 글을 마무리 하겠습니다. 새해 복 많이 받으세요. ^^