Overview
MySQL의 꽃중의 꽃은 역시 비동기 방식의 데이터 복제라고 볼 수 있는데요. 지극히 개인적인 생각이기는 하지만, 슬레이브 노드를 데이터 일관성이 반드시 필요한 상황에서의 READ 스케일아웃을 “제외”하고는, 지금의 MySQL을 있게한 결정적인 한방이라고 봅니다. 물론 소셜 서비스에 따른 기존 스케일업으로는 도저히 감당할 수 없는 데이터 사이즈와 비용 요소도 직접적인 영향을 주었겠지만요.
뜬구름잡는 얘기는 여기까지로 마무리하고.. 슬레이브 노드를 READ 분산 혹은 배치 서버 용도를 제외하고는 스탠바이 용도로 한대를 더 추가하는 경우는 극히 드뭅니다. 뭐, 나랏님이 시키는대로.. 반드시 수십 km 떨어진 IDC에 DR 서버를 구축해야한다는 “법적인 제약”인 경우를 제외하고는요.
이유야 어쨌든, 이전 운영하는 서버 클러스터 노드와는 다르게 3대의 DB 서버를 세트 하나로 구성하게 되었는데요. 나름 고민에 고민을 거쳐, 최종적으로 현재 구조로 마무리하면서 얻게된 잇점과 효율에 대해서 얘기를 풀어보도록 하겠습니다.
2-Nodes vs 3-Nodes
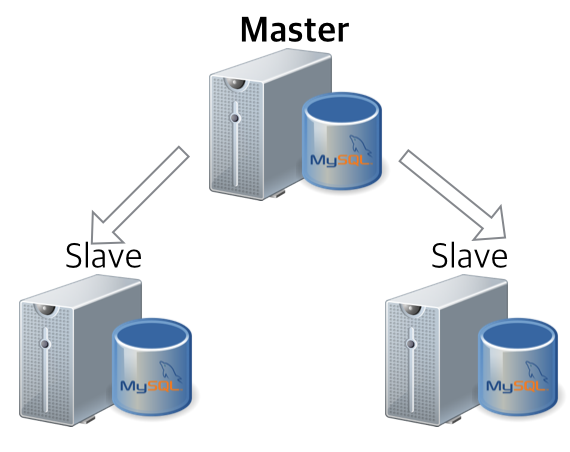
서버를 두대로 구성하는 경우는 일반적으로 아래와 같이 마스터/슬레이브 구조로 데이터를 복제하는 경우입니다. 평시에는 Master에서 모든 서비스를 하고 장애 시 슬레이브로 커넥션을 (자동이든/수동이든) 넘겨서 서비스 다운타임을 최소화하기 위함입니다. 데이터가 논리적으로 복제가 되기 때문에, 슬레이브를 활용하여 꽤 무거운 배치 혹은 데이터 처리를 서비스 영향없이 수행 가능합니다.

비슷하게 비슷한 목적을 가졌지만, 앞선 경우에는 데이터를 논리적으로 복제를 해서 원격에 데이터를 위치시키는 것과 다르게, 스토리지를 활용하여 서버 장애에 대응한 경우도 있습니다. 이 경우 아쉽게도 서버 장애에는 대응이 가능하나, 스토리지 장애에는 “스토리지 이중화”외에는 방안이 없으며, 스탠바이 노드는 디비 데몬이 내려가 있기 때문에, 정말 1도 활용할 수 없다는 아쉬움이 남습니다. 게다가 “물리적으로 저장공간을 공유”하는 구조이기 때문에, NIC를 통해 논리적으로 데이터를 복사하는 앞선 경우와는 다르게 “스토리지 물리적인 장소”에 영향을 받을 수밖에 없습니다.
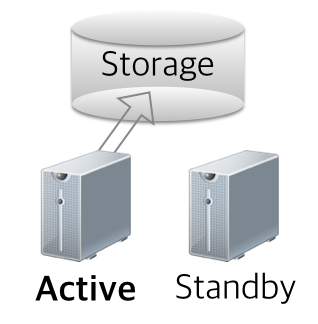
일반적으로 2대의 노드로는 위 두 가지 경우를 크게 벗어나는 경우는 없습니다. 두가지 경우 모두 둘 중 하나만 서비스에 투입이 되기 때문에, 한대는 거의 대부분 서비스에 직접적인 트래픽을 받지 않습니다. (뭐 첫번째 경우 배치 쿼리 정도는 날려볼만 하겠지만요.)
그러나 타의든 자의든, 일단 세 대를 아래와 같은 형태로 운영을 해야하는 상황이 도래합니다. 아래와 같이 3대 노드로 데이터를 구성하는 경우, MySQL은 세트 하나 늘어날 시에 세대씩 증가하기 때문에관리 포인트는 2-노드인 경우보다 훨씬 많아집니다. 게다가 MySQL의 꽃은 샤딩.. 무한 확장을 꿈꾸며 데이터 라우팅을 지대로 하는 것이 묘미니까요. ㅎㅎ
또한 노드가 늘어남에 따라 “복제 시 전송되는 로그양”도 적은 비용이 아닙니다. (금전적인 것 이외에도 말입니다.)
사용하지 않을 장비만 늘어나고, 이에 따라 관리 포인트만 증가하는 현실 속에서, 이 글을 쓰기 시작하였고, 어찌됐건 기존 1M-1S 구조에서와는 다른 “얻은점”에 대해서 얘기를 풀어보도록 하겠습니다. (공감하신다면, 야밤에 박수 세번 짝짝짝)
1. Semi-Sync Replication
데이터 자체가 굉장히 민감한 서비스(이를테면, 돈이 오가는 서비스)에서는, 절대적으로 데이터의 유실은 허용될 수 없습니다. 트랜잭션이 실패할지라도, 장애 시 데이터 유실은 상상조차 해서는 안되는 것이죠.
MySQL5.5 부터는 이런 현상을 최소화하기 위해, semi-sync replication 기술을 도입하였습니다. 이는 마스터와 슬레이브 간의 데이터 동기화를 100% 보장할 수는 없지만, 적어도 복제 로그(릴레이로그)에 대한 보장을 어느정도 하겠다는 것을 의미합니다.
일반적으로 5.5부터 언급되는 MySQL semi-sync는 “AFTER_COMMIT”모드로, 커밋 이후 사용자에게 응답을 주기 직전(엔진에는 이미 데이터 적용 완료)에 잠시 슬레이브 릴레이 로그를 기다리는 형태로 동작을 하였습니다.
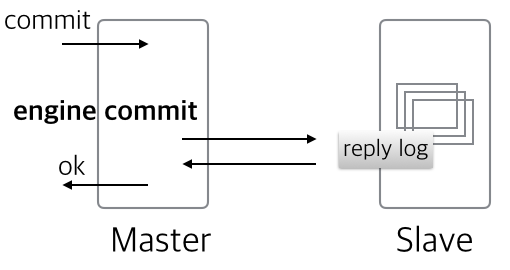
MySQL 5.7.2 부터는 Lossless Replication이라는 멋진 이름 하에 “AFTER_SYNC”모드의 semi-sync 옵션이 추가가 되었는데, 간단하게 얘기하자면, 엔진에 커밋이 되기 직전에 슬레이브 릴레이 로그 저장을 잠시 기다려보겠다는 것을 의미합니다. (아래 빨간 글씨)

그런데, AFTER_SYNC든 AFTER_COMMIT이든 공통적으로 가지는 문제가 하나 있는데.. “트랜잭션 응답 시간이 슬레이브의 빠른 응답에 의존적”이라는 것입니다. 만약, 슬레이브가 한 대인 상황에서 “슬레이브”가 장애가 나게 된다면, 서비스 트랜잭션이 일시적으로 블록킹 형태로 머물러있게 됩니다.
물론 rpl_semi_sync_master_timeout 파라메터를 조정해서, 슬레이브의 응답을 기다리는 최대 시간을 조정하여, 빠르게 Async모드로 돌아오도록 조정할 수 있지만.. 기본값이 10초인 상황을 인지 못한 채, 운영하다보면 영문도 모른채 서비스에 이상을 감지할 수 있습니다. (여기서, 분명히 구분해야할 것은, 서비스 투입되지 않은 “슬레이브” 이상으로 발생하는 상황이라는 점입니다.)
그런데, 슬레이브 노드 하나를 더 추가함으로써 “특정 슬레이브 노드의 지연”이 마스터의 트랜잭션 지연으로 이어지지 않습니다. 둘 중 한군데에서 응답이 오면 마스터는 더이상 기다리지 않고 트랜잭션을 완료 처리하기 때문이죠. 물론 몇 군데의 응답을 기다릴지도 옵션으로 지정할 수 있지만, 굳이 그럴 이유는 없어보입니다. (이유는 MHA에서..)
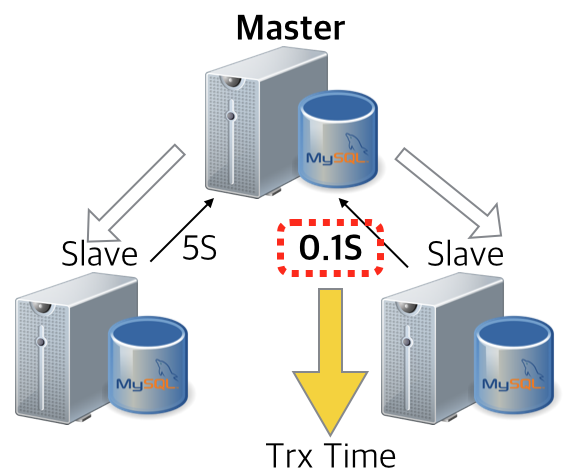
슬레이브 하나를 더 추가했을 뿐인데.. semi-sync 를 더욱 안정적으로 멋지게 사용할 수 있는 발판이 되었습니다. 눈누난나~
2. Backup & Restore
백업/복구.. 데이터 솔루션을 운용하는 입장에서는 반드시 초반부터 계획을 잡아야하는 상황인데요. 앞선 블로그 “세상만사 귀찮은 MySQL DBA를 위한 자동 복구 시나리오” 에서 어떻게 자동화를 하는지에 대해서 공유한 적이 있었습니다. 슬레이브를 한대 더 추가함으로써 복구 시 서비스 품질 관련하여 곁다리로 하나 더 얻게된 점이 하나 더 있는데요.
이전에 슬레이브 한대로만 서비스를 운영한다면, 마스터 장비 페일오버 이후 데이터 복구 수행 시, 그 날 새벽 백업 데이터를 활용하여 슬레이브를 복구해야만 합니다. 물론, (서비스에 투입된)마스터에서 직접 받아와도 되겠지만, 수백기가 데이터를 전송하는 동안 네트워크 트래픽을 비롯해서 디스크 I/O를 고려한다면, 서비스 안정성 측면에서 좋은 선택을 아니라고 봅니다.
새벽 데이터로 슬레이브 구성을 한다는 말은 곧, 새벽부터 쌓이기 시작한 “바이너리로그”를 모두 끌어와서 현재 시점까지 리플레이하여 적용하겠다는 말인데요. 굉장히 바쁜 서버 경우에는 하루 70~80G이상 바이너리 로그가 쌓이기도 하는데.. 가져오는 것도 부담일 뿐만 아니라, 적용하는 시간 조차도 굉장히 부담이 됩니다. (23시간 전의 데이터로 복구를 한다고 생각을 해보세요. 바쁜서버는 10시간 넘게도 걸릴 수도 있습니다.)
자. 여기서 슬레이브를 하나 더 추가를 해보았다면, 어떤 것을 얻을 수 있을까요? 슬레이브 구성이 필요한 상황이 오더라도, 아래와 같이 슬레이브로부터 데이터를 받아와서 바로 원래 구조로 쉽게 돌아갈 수 있게 됩니다. 서비스 영향도는 거의 제로에 가깝게.. 굳굳굳
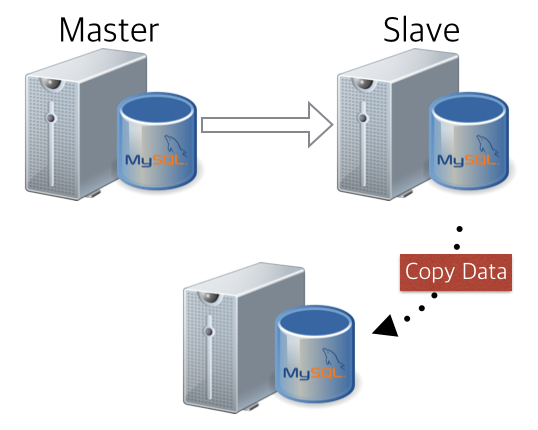
3. Collaboration with MHA
개인적인 관점에서.. MHA야말로 신의 한 수라고 생각합니다.ㅋㅋ
MHA? 개념이 아직 생소하신 분도 있겠죠. 간단하게 설명하자면, MHA는 Master의 헬스 체크를 주기적(3초단위 쿼리를 날리면서)으로 수행하면서, 설정된 카운트 이상 실패 시 스탠바이 슬레이브로 마스터의 롤을 체인지시켜주는 “요시노리”가 오픈소스로 공개한 MySQL HA 솔루션입니다.
재미있는 것은 MHA가 마스터 장애를 감지하고, 슬레이브로 마스터의 롤을 넘기는 과정에서 살아있는 슬레이브들의 리플리케이션 또한 신규 마스터 기준으로 재구성을 해주는데요. 이 경우 기존 마스터로부터 전달받은 릴레이 로그를 비교 및 버전 동기화를 함으로써 최종적으로 정상적인 리플리케이션 형태로 만들어줍니다.
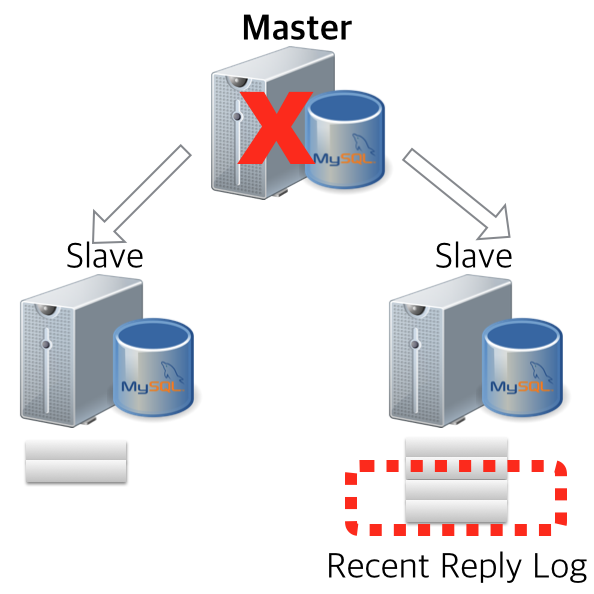
“릴레이 로그”를 비교한다라는 것은.. 앞서 1번에서 언급했던 “Semi-Sync Replication”을 생각해볼 수 있는데요. Semi-Sync로 구성된 리플리케이션 클러스터 내부에서는.. “커밋된 트랜잭션”의 릴레이 로그는 “슬레이브 어디엔가에는 반드시 존재한다”는 가정하에 동작합니다.
AFTER_SYNC 모드로 semi-sync를 운영하고 있다면, 커밋된 트랜잭션의 릴레이로그는 “슬레이브 중 어딘가”에는 반드시 존재할 것이고, 이 경우 마스터 장애 시 “어딘가에 존재하는 릴레이로그”를 활용한 복구로 절대적으로 데이터 유실 가능성은 제로에 가깝게 될 것이다라고 돌려 말을 해봐도 되겠습니다.
4. High Availability
2번 백업에서도 얘기했던 것과 일맥상통하는 얘기일 수 있겠습니다.
슬레이브가 한대인 경우에 마스터 장애가 발생했을 시에는 늘 걱정되는 것이 바로 2차 장애였습니다. 장애 후 복구까지는 어찌됐건 싱글 DB로 데이터를 운영하고 있는 것이고.. 이 한대에 이슈가 발생하면 “메가톤급 서비스 장애”와 “데이터 유실”이라는 부담감을 가지고 늘 지내왔죠. 그렇기때문에, 새벽 몇시가 되건 “유휴장비”를 시스템부서로부터 제공받아 빠르게 슬레이브를 붙이는 것이 장애 대응 1순위 작업이었죠. 서비스는 소중하니까요. 🙂
그런데, 슬레이브를 하나 더 붙였을 뿐인데.. 2차 장애에 대응해서 우리에게는 하나 더 선택지가 생겼습니다.
- MHA를 2노드로 설정해서 다시 모니터링한다.
- 모니터링을 하지 않되, 문제 시 바로 남은 슬레이브로 롤체인지 한다.
이 두가지 모두, 정책적으로 운영을 어떻게 할 지에 대한 선택일 뿐, 2차 장애에 대한 대응은 동일합니다. 다른 점이라면, 자동으로 넘길지 혹은 수동으로 확인하고 넘길지 두 가지 입니다. 2차 장애에 대응할 수 있는 새로운 선택지가 생겼다는 사실은 운영 부담을 압도적으로 줄일 수 있는 계기가 되었습니다.
5. ETC
이것말고도 생각해보면 많습니다. 정말로 사용하지 않는 슬레이브에 개발자 접근 권한을 줘서 “무슨 짓”을 하든 적어도 서비스 간접적인 영향마저도 최소화 한다거나.. 엄청난 쿼리를 한번 날려본다거나..
Conclusion
슬레이브를 하나 더 추가했을 뿐인데.. 생각보다 많은 것을 얻었습니다.
- MHA+semi-sync로 데이터 신뢰성과 안정성
- 2차 장애에 대한 가용성 정책
- 백업/복구 효율성
물론 한대 더 추가함으로써 운영 리소스가 더 들어갈 수 있습니다. 그러나. 이런 것들은 자동화함으로써.. “다수 서버 운영 시 허들이 될만한 부분은 모두 “잔머리 굴려서” 자동화” 하면 되겠죠. 실제 제가 운영하고 있는 서비스에서는 “정말 크리티컬한 명령”을 제외하고는 자동화하는 정책을 굉장히 지향하고 있습니다.
서비스 특성에 따라 이것이 정답은 아니겠지만, 제가 운영하는 “OLTP 위주”의 “데이터 신뢰”가 대단히 중요한 서비스에서는 꽤나 좋은 데이터 프로세싱 “철학”이자 새로운 “경험”이라 생각해봅니다.
간만에 긴 주저리 블로깅이었습니다. 짝짝짝~! 좋은 주제로 다시 만나용~