Overview
MySQL과 같은 RDBMS에서 대표적으로 가장 많이 사용되는 자료 구조는 B-Tree입니다. 데이터 사이즈가 아무리 커져도 특정 데이터 접근에 소요되는 비용이 크게 증가되지 않기 때문에 어느정도 예상할 수 있는 퍼포먼스를 제공할 수 있기 때문이죠. 그치만 상황에 따라서, B-Tree 사용에 따른 잠금 현상으로 최대의 퍼포먼스를 발휘하지 못하는 경우도 있습니다.
이에 대한 해결책으로 InnoDB에는 Adaptive Hash Index 기능이 있는데, 어떤 상황에서 효과가 있고 사용 시 반드시 주의를 해야할 부분에 대해서 정리해보겠습니다.
InnoDB B-Tree Index?
소개하기에 앞서서 먼저 InnoDB에서 B-Tree가 어떠한 방식으로 활용되는 지 알아볼까요?
InnoDB에서는 데이터들은 Primary Key순으로 정렬이 되어서 관리가 되는데.. 이것을 곧 PK로 클러스터링 되어 있다라고 합니다. 데이터 노드 자체가 PK 순으로 정렬이 되어있다는 말인데, 이는 곧 특정 데이터에 접근하기 위해서는 PK가 반드시 필요하다는 말이지요.
그리고 Secondrary Key는 [인덱스키+PK]를 조합으로 정렬이 되어 있습니다. 즉, 특정 데이터를 찾기 위해서는 Secondrary Key에서 PK를 찾아내고, 그 PK를 통해 데이터 트리로 접근하여 원하는 데이터로 최종 접근을 하는 것이죠.
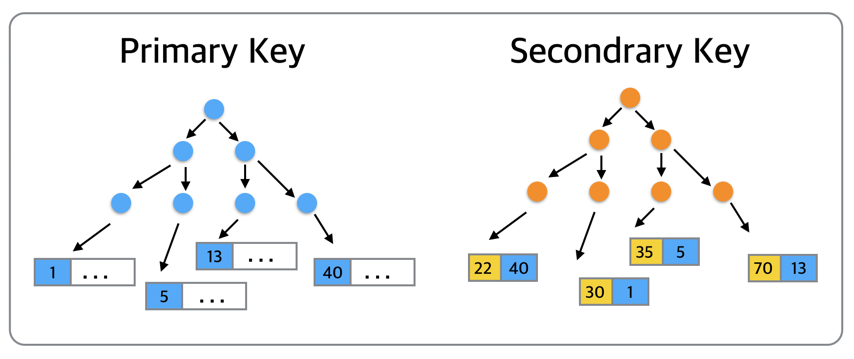
트리가 가지는 가장 큰 장점은, 데이터 접근 퍼포먼스가 데이터 증가량에 따라서도 결코 선형적으로 증가하지 않다는 점에 있습니다. 다들 아시겠지만, B-Tree에서 특정 데이터 접근에 소요되는 비용은 O(logN)인데, 이는 일정 데이터 건 수에서는 거의 선형으로 비용이 유지됩니다. (참고로, PK접근 시에는O(logN), Secondrary Key ㅈ버근 시에는 2 *O(logN) 이겠죠?)
그런데, B-Tree를 통하여 굉장히 빈도있게 데이터로 접근한다면, 어떻게 될까요? DB 자체적으로는 꽤 좋은 쿼리 처리량을 보일지는 몰라도, 특정 데이터 노드에 접근하기 위해서 매번 트리의 경로를 쫓아가야하기 때문에, “공유 자원에 대한 잠금”이 발생할 수 밖에 없습니다. 즉, Mutex Lock이 과도하게 잡힐 수 있는데, 이 경우 비록 데이터 셋이 메모리보다 적음에도 불구하고 DB 효율이 굉장히 떨어지게 됩니다.
InnoDB Adaptive Hash Index?
앞선 상황에서 좋은 성능을 보이기 위해서, InnoDB에서는 내부적으로 Adaptive Hash Index 기능을 제공합니다. “Adpative”라는 말에서 느껴지듯이, 이 특별한 자료구조는 명쾌하게 동작하지는 않고, “자주” 사용되는 데이터 값을 InnoDB 내부적으로 판단하여 상황에 맞게 해시를 생성” 합니다.
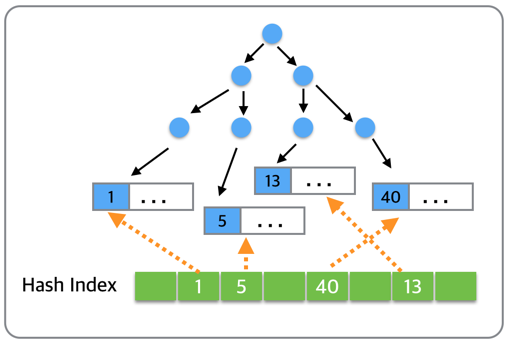
위 그림에서 자주 사용되는 데이터들이 1,5,13,40이라고 가정할 때 위와 같이 내부적으로 판단하여 트리를 통하지 않고 “직접 원하는 데이터로 접근할 수 있는 해시 인덱스”를 통해 직접 데이터에 접근합니다.
참고로, Adative Hash Index에 할당되는 메모리는 전체 Innodb_Buffer_Pool_Size의 1/64만큼으로 초기화됩니다. 단, 최소 메모리 할당은 저렇게 할당되나, 최대 사용되는 메모리 양은 알 수는 없습니다. (경우에 따라 다르지만, Adaptive Hash Index가 사용하는 인덱스 사이즈를 반드시 모니터링해야 합니다.)
이 기능은 MySQL5.5버전(InnoDB Plugin 1.0.3)부터는 이 기능을 동적으로 On/Off할 수 있습니다. 아래와 같이.. ^^;;
## 켜다 mariadb> set global innodb_adaptive_hash_index = 1; ## 끄다 mariadb> set global innodb_adaptive_hash_index = 0;
관련 통계 정보는 아래와 같이 확인..ㅋ
mariadb> show global status like 'Innodb_adaptive_hash%'; +----------------------------------------+------------+ | Variable_name | Value | +----------------------------------------+------------+ | Innodb_adaptive_hash_cells | 42499631 | | Innodb_adaptive_hash_heap_buffers | 0 | | Innodb_adaptive_hash_hash_searches | 21583 | | Innodb_adaptive_hash_non_hash_searches | 3768761684 | +----------------------------------------+------------+
자주 사용되는 데이터는 해시를 통해서 직접 접근할 수 있기에, Mutex Lock으로 인한 지연은 확연하게 줄어듭니다. 게다가 B-Tree의 데이터 접근 비용(O(LogN))에 비해, 해시 데이터 접근 비용인 O(1)으로 굉장히 빠른 속도로 데이터 처리할 수 있습니다.
단, “자주” 사용되는 자원만을 해시로 생성하기 때문에, 단 건 SELECT로 인하여 반드시 해당 자원을 향한 직접적인 해시 값이 만들어지지 않습니다.
InnoDB는 Primary Key를 통한 데이터 접근을 제일 선호하기는 하지만, 만약 PK접근일지라도 정말 빈도있게 사용되는 데이터라면 이 역시 Hash Index를 생성합니다. (처음에는 단건 PK 접근에는 절대로 Hash Index를 만들지 않을 것이라 생각했지만, 곧 생각을 고쳐먹었습니다. ㅋㅋ)
Adaptive Hash Index Power!!
흠.. 말만 하지말고.. 눈에 보이는 효과를 보도록 할까요? 글빨이 안되니.. 비주얼로 승부를!!ㅋㅋ
아래와 같이 간단한 테스트 케이스(1300만 건 데이터)를 만들어서, IN 조건으로 PK를 통하여 데이터를 추출하는 테스트를 해보도록 해요. IN절에는 약 30개 정도의 파라메터를 넣고, 300개의 쓰레드에서 5ms 슬립을 줘가며 무작위로 트래픽을 보내봅니다.ㅋㅋ
## 테이블 스키마 create table ahi_test( i int unsigned not null primary key auto_increment, j int unsigned not null, v text, key ix_j(j) ); ## SELECT 쿼리 select left(v, 1) from ahi_test where i in (x,x,x,x,x,...x,x,x,,);
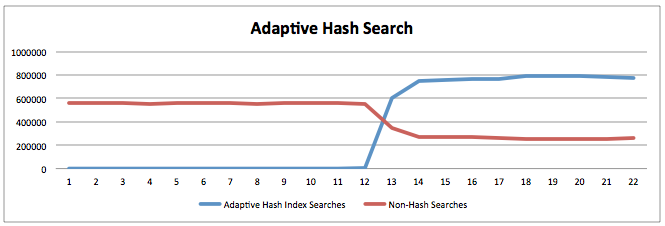
Adaptive Hash Index를 사용하지 않는 오른쪽 결과에서는 CPU가 100%였으나, Adaptive Hash Index를 사용한 이후에는 60%정도로 사용률이 내려갔습니다.
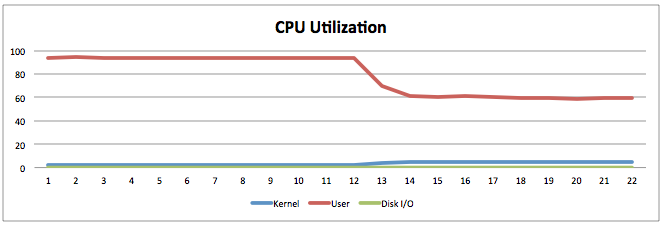
게다가, CPU는 줄었으나, 쿼리 응답 시간이 줄었기에 처리량 또한 20,000 -> 37,000으로 늘어났습니다. 참으로 놀라운 결과지요?? ㅋㅋ
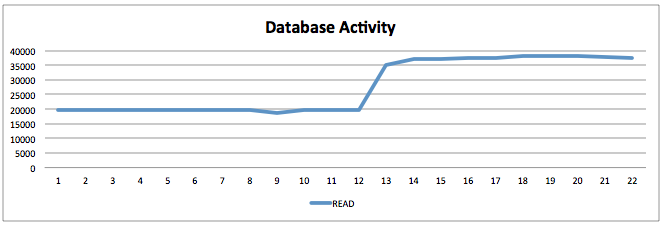
Adaptive Hash Index를 켠 이후에는 확실히 B-Tree를 통해서 데이터에 접근하는 빈도가 줄어든 것도 확인할 수 있고요~
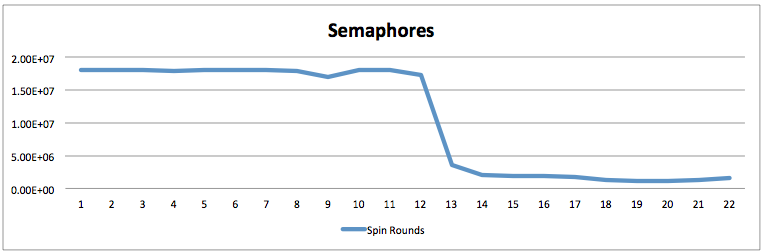
이에 따라 내부적인 잠금 현상도 확연하게 줄어들었습니다.
다른 것은 손대지 않고, Adaptive Hash Index만 켰을 뿐인데….
결론은 따~봉!! 굉장히도 풍요로운 꽁짜 점심이죠? ㅋㅋ
Cautions
자.. 이제 InnoDB Adaptive Hash Index 효과를 보았으니, 영혼없이 아무 곳에서나 무조건 쓰도록 할까요? 노노~! InnoDB Adaptive Hash Index 가 필요할 정도라면, SELECT가 꽤 많이 발생하는 서비스라고 생각해볼 수 있는데요.. 이 상황에서 테이블 DROP시 문제가 발생할 수 있습니다.
아래 그림은 percona-online-schema-change 툴을 활용하여 스키마를 변경한 전/후 Adaptive Hash Index사이즈를 체크한 것인데, 전후로 두 배로 해시 사이즈가 증가하였습니다. 그런데 두 배가 문제가 되기보다는, 아래와 같은 상황이 수 개월 동안 유지될 수 있다는 점입니다.
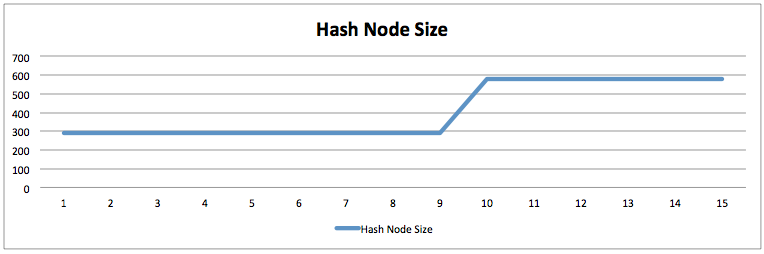
평소 운영 시에는 전~혀 문제가 되지 않지만, 수 개월동안 전~혀 사용하고 있지 않던 테이블을 영혼없이 정리하다보면 치명적인 장애에 직면할 수 있는 것이죠. 바로 저처럼.. -_-;;
아래 수치는 앞선 테스트 테이블에 트래픽을 주는 상황에서 OLD 테이블을 DROP하였는데, 테이블 정리 도중에는 처리량이 급감(3.8만 -> 2.7만)한 상황을 보여줍니다. 아래 현상이 굉장히 많은 SELECT가 발생하던 서버에서 발생을 하였다면, 단위 쿼리 처리량이 줄어듬에 따라 어플리케이션 쪽에 문제가 발생할 수도 있겠죠. ㅠㅠ
| Com_select | 39041 | | Com_select | 39189 | | Com_select | 38774 | | Com_select | 38953 | | Com_select | 39527 | | Com_select | 37906 | | Com_select | 39316 | | Com_select | 37541 | | Com_select | 37972 | | Com_select | 32484 | <=== DROP OLD TABLE START | Com_select | 27514 | | Com_select | 27602 | | Com_select | 27692 | | Com_select | 27918 | | Com_select | 27818 | | Com_select | 28266 | | Com_select | 28383 | | Com_select | 28350 | | Com_select | 37047 | <=== DROP OLD TABLE END | Com_select | 39572 | | Com_select | 38868 | | Com_select | 39315 | | Com_select | 38738 | | Com_select | 39548 | | Com_select | 39413 | | Com_select | 38978 |
설혹, 데이터가 2G일지라도, 또한 파일 시스템이 xfs일지라도.. 이것은 디스크적인 요소라기 보다는 Memory 내부적인 잠금 이슈이기 때문에.. 어찌 해결해볼 방법은 없습니다.
InnoDB 내부적으로는 테이블 DROP시 Sleep없이 죽어라고 Hash Index에서 관련 노드를 모두 삭제한 후 테이블이 제거합니다. 그런데 이것이 단일 Mutex로 관리되기 때문에 기존 SELECT 성능에도 지대한 영향을 끼치는 것이죠. 그나마 최대한 이러한 현상을 회피할 수 있는 방법은 innodb_adaptive_hash_index_partitions을 수십개(기본값은 1)로 늘려놓고, 경합을 최대한 줄이는 방법만이 유일할 듯하네요. ^^ (테이블 드랍은 트래픽이 제일 없을 때로!!)
아.. 혹은 테이블 드랍을 수행할 때는 최대한 트래픽이 없는 새벽에, Adaptive Hash Index를 순간 OFF/ON을 하여 메모리를 해제하고, 테이블을 DROP하는 방법도 될 수 있겠네요. ^^ 선택은 서비스 상황에 맞게..
InnoDB Adaptive Hash Index가 사용하는 메모리 사이즈도 지속적으로 모니터링을 해야할 요소라는 것도 잊지 말아야할 것이고요. ^^
Conclusion
InnoDB Adaptive Hash Index는 B-Tree의 한계를 보완할 수 있는 굉장히 좋은 기능임에는 틀림 없습니다. 특히나 Mutex와 같은 내부적인 잠금으로 인한 퍼포먼스 저하 상황에서는 좋은 튜닝요소가 될 수 있습니다.
그러나, “자주” 사용되는 데이터를 옵티마이저가 판단하여 해시 키로 만들기 때문에 제어가 어려우며, 테이블 Drop 시 영향을 줄 수 있습니다. Hash Index 구조가 단일 Mutex로 관리되기 때문에, 수개월간 테이블이 사용되지 않던 상황에서도 문제가 발생할 수 있는 것입니다.
굉장한 SELECT를 Adaptive Hash Index로 멋지게 해결하고 있다면, 이에 따른 Side Effect도 반드시 인지하고 잠재적인 장애에 대해서 미리 대비하시기 바래요. ^^