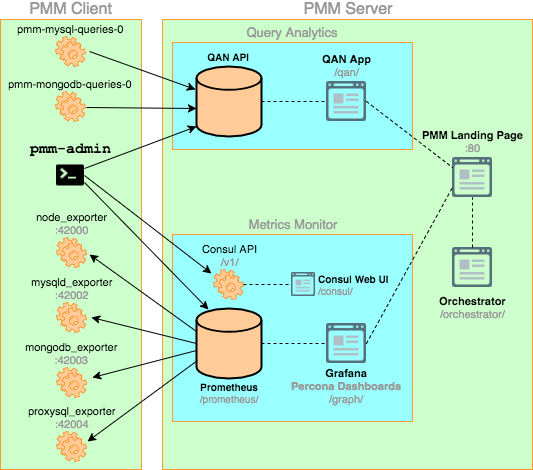
Overview
이제 슬슬 날이 풀려가고 있습니다. 얼어붙은 땅이 녹듯이, 오랜시간 얼어있던 블로그 공간도 잠시마나 녹여볼까 합니다. 사실 지난 “PMM 이야기 1편” 이후 2편, 3편 쭉 써야하지만.. 이노무 귀차니즘과 여기저기 산재한 낙서들을 아직 정리하지 못한 탓에.. 쿨럭..
사실 오늘 얘기할 내용은 3년도 훨씬 전 내용으로, 블로그로 이미 정리했다고 지금까지 착각을 했던 이야기입니다. 바로 “Affected Rows” 값을 활용해서, 다양한 요구 사항을 조금 더 재미있게 풀어보자는 내용이죠.
Affected Rows?
다들 아시겠지만, Affected Rows는 DML시 실제로 영향을 미친 데이터 Row 수입니다. 보통 update/delete를 날린 후에 몇 건의 데이터가 변경이 되었는지를 CLI툴에서 확인하는 용도로만 “제 경우”에는 많이 사용하고는 했습니다.
참고로 MySQL에서 Affected Rows는 “정말로 데이터가 변경”된 경우에만 반영되며, 하단과 같이 기존 데이터에 변화가 없는 경우에는 Affected Rows는 0건으로 보여집니다. (이 내용은 중요해요!)
mysql> insert into test values (1,1);
Query OK, 1 row affected (0.00 sec)
mysql> update test set j = 1;
Query OK, 0 rows affected (0.01 sec)
Rows matched: 1 Changed: 0 Warnings: 0
mysql> update test set j = 2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL만 제공하는 다음 두 개 쿼리는 조금 재미있게 동작합니다.
REPLACE INTO .. VALUES ..
INSERT INTO .. ON DUPLICATE UPDATE ..
REPLACE 구문은 우선 넣고자 하는 데이터와 충돌이 되는 ROW는 DELETE 후 INSERT하는 특성을 가집니다. 트리거 기반의 온라인 스키마 변경 툴 중 대표적인 pt-online-schema-change의 INSERT/UPDATE 트리거 이벤트는 REPLACE로 되어 있죠. (방해꾼 PK/UK가 없으면, 그냥 계속 누적 INSERT됩니다.ㅋㅋ)
INSERT INTO .. ON DUPLICATE UPDATE .. 는 PK 혹은 UK로 인한 중복된 값 에러 발생 시 이를 뒤에 명시한 값으로 데이터를 업데이트하라는 의미입니다. (다들 아실꺼예요.) 없으면 알아서 초기화하고, 있으면 업데이트하는 형식의 굳이 초기화할 필요없는 통계 테이블을 관리하는 용도로 사용한다고나할까.. -_-;
오늘 재밌게 가지고 놀 녀석은 바로 두 번째 녀석 “INSERT INTO .. ON DUPLICATE UPDATE”입니다.
Crazy Question
벌써 3년도 더 된 이야기네요. 엯촋 개발자 분에게 아래와 같은 질문을 받습니다.
(1)일정 주기에 따라 이벤트 참여 (2)카운트를 제한하고 싶어요~!
하루 혹은 일정 주기에 따라 이벤트 등록 횟수를 제한하고자 하는 요구사항입니다. 예를들어 한 시간 기준 이벤트을 생각해본다면, 매 0시마다 지금까지 이벤트 참여 카운트는 초기화하고, 다시 정해진 수만큼 응모를 하는 그런 형태의 요구사항이죠. 아.. 물론.. 어플리케이션 레벨에서 트랜잭션을 구성한다면, 아래와 같이 생각해볼 수 있을 것 같네요. (그냥 막 쓴 것 아시죠? ㅋㅋ)
try{
execute("BEGIN");
row = execute("SELECT * FROM user_event WHERE user_id = 100 FOR UPDATE");
// 1. 시간 적절성 체크
if(last_applied_time == CURRENT_DATE){
// 2. 카운트 적절성 체크
if(apply_count < 5){
execute("UPDATE user_event SET apply_count = apply_count + 1 WHERE user_id = 100");
}
}else{
// 3. 데이터 초기화
execute("UPDATE user_event SET apply_count = 1 WHERE user_id = 100");
}
execute("COMMIT");
}catch(Exception e){
execute("ROLLBACK");
}
뭐, 저렇게 하면 되니까.. 저렇게 풀어도 되겠지만.. 이런 처리를 조금 더 병맛나고 재미있게 풀어볼계요.
My Solution
자, 우선.. 테스트 하기에 앞서 테이블을 하나 생성합니다. 구조가 참 간단하쥬?
CREATE TABLE `user_event` (
`user_id` int(11) NOT NULL,
`apply_count` int(11) NOT NULL,
`last_applied_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB
그냥, 사용자 기준응모 카운트와 마지막 응모 시간(타임스탬프)을 가지는 지극히 간단한 테이블입니다. 이제, 요구 사항에 맞게 쿼리를 아래와 같이 만들어보겠습니다. 우선은 데이터가 없을 수 있으니, INSERT 합니다.
INSERT INTO user_event (user_id, apply_count) VALUES (1, 1) ;
문제는 그 다음에도 동일한 사용자에 대한 처리를 위해서 ON DUPLICATE KEY UPDATE로 apply_count를 업데이트 관리합니다.
INSERT INTO user_event (user_id, apply_count) VALUES (1, 1)
ON DUPLICATE KEY UPDATE apply_count = apply_count + 1
그런데 매일 0시마다 초기화를 해야 하겠죠? 마지막 응모 날짜와 오늘 날짜가 동일하면 응모 카운트를 증가합니다. (1)일정 주기를 만족하기 위해서, 아래와 같이 if로 분기 처리합니다.
INSERT INTO user_event (user_id, apply_count) VALUES (1, 1)
ON DUPLICATE KEY UPDATE
apply_count = if(date(last_applied_time) = current_date, apply_count + 1, 1)
이제 마지막입니다. (1)일정 주기 조건은 앞에서 맞췄으니, 이번에는 (2)카운트를 제한 조건을 아래와 같이 맞춰봅시다. apply_count는 현재 값이 5보다 작을 때만 1 올리자는 얘기지요.
INSERT INTO user_event (user_id, apply_count) VALUES (1, 1)
ON DUPLICATE KEY UPDATE
apply_count = if(date(last_applied_time) = current_date, if(apply_count < 5, apply_count + 1, apply_count), 1)
이렇게 꼼수같은 꼼수같은 꼼수를 통해, 단 한줄의 쿼리로 원하는 요구사항을 충족시켜 보았습니다.
- user_id(pk)를 포함한 데이터를 INSERT
- PK 중복 시, 정해진 기간 내에 존재한다면,
- 카운트가 유효하다면, 응모 카운트 1 증가
- 정해진 카운트 도달 상태면 아무것도 안함
- PK 중복 시, 정해진 기간 밖에 있다면,
- 응모 건 수를 초기화
자.. 쿼리 요구사항은 맞췄으니, 이제 Affected Rows에 따라 처리 결과를 분기 처리해봐야겠죠? 테스트를 위해 위 쿼리처럼 하루를 기다릴 수 없으니, 시간을 초단위(10초)로 구성해서 반복 수행해봅니다. (아래 쿼리 예시)
INSERT INTO user_event (user_id, apply_count) VALUES (1, 1)
ON DUPLICATE KEY UPDATE
apply_count = if(timestampdiff(second, last_applied_time, now()) < 10, if(apply_count < 5, apply_count + 1, apply_count), 1)
그리고 아래와 같이 예쁜 결과를 얻어봅니다. 어플리케이션에서는 쿼리 결과로 전달받는 Affected Rows 값에 따라, 이 사람이 응모가 되었는지(1 이상), 제한된 상황인지(0)를 판단하면 되겠습니다.
mysql> INSERT INTO user_event .. ON DUPLICATE KEY UPDATE ..
Query OK, 1 row affected (0.00 sec) <= 없던 데이터
mysql> select * from user_event;
+---------+-------------+---------------------+
| user_id | apply_count | last_applied_time |
+---------+-------------+---------------------+
| 1 | 1 | 2018-03-25 23:05:38 |
+---------+-------------+---------------------+
mysql> INSERT INTO user_event .. ON DUPLICATE KEY UPDATE ..
Query OK, 2 rows affected (0.00 sec) <= 있는 데이터
mysql> select * from user_event;
+---------+-------------+---------------------+
| user_id | apply_count | last_applied_time |
+---------+-------------+---------------------+
| 1 | 2 | 2018-03-25 23:05:41 |
+---------+-------------+---------------------+
.. 중략 ..
mysql> INSERT INTO user_event .. ON DUPLICATE KEY UPDATE ..
Query OK, 0 rows affected (0.00 sec) <= 조건에 맞지 않음
mysql> select * from user_event;
+---------+-------------+---------------------+
| user_id | apply_count | last_applied_time |
+---------+-------------+---------------------+
| 1 | 5 | 2018-03-25 23:05:46 |
+---------+-------------+---------------------+
.. 중략 ..
mysql> INSERT INTO user_event .. ON DUPLICATE KEY UPDATE ..
Query OK, 2 rows affected (0.00 sec) <= 초기화
mysql> select * from user_event;
+---------+-------------+---------------------+
| user_id | apply_count | last_applied_time |
+---------+-------------+---------------------+
| 1 | 1 | 2018-03-25 23:05:56 |
+---------+-------------+---------------------+
즉 정리를 해보면.. 아래와 같은 동작을 기대해볼 수 있겠습니다. ^^ 단, 자바에서는 이런 이쁜 결과를 받아보기 위해서는 useAffectedRows=true 파라메터를 줘야합니다. (관련: https://bugs.mysql.com/bug.php?id=39352)
Query OK, 1 row affected (0.00 sec) <= 신규 ROW insert : 1
Query OK, 2 rows affected (0.00 sec) <= 데이터 업데이트 : 2
Query OK, 2 rows affected (0.00 sec) <= 데이터 업데이트 : 3
Query OK, 2 rows affected (0.00 sec) <= 데이터 업데이트 : 4
Query OK, 2 rows affected (0.00 sec) <= 데이터 업데이트 : 5
Query OK, 0 rows affected (0.00 sec) <= 데이터 변경 없음Conclusion
데이터에 변경 사항이 없으면 Affected Rows 변화량 또한 없는 것은 MySQL의 고유 특성입니다. 이것은 DBMS에 따라 다르게 동작하기 때문에, MySQL에 (아마도) 의존적이죠.
그러나 이런 동작을 이해하고 활용해본다면, 더욱 병맛나는 문제도 해결할 수 있습니다. 일정 기간 응모 횟수를 제한하는 것 뿐만 아니라, 일단위 혹은 월단위 통계 테이블을 유지하는 것이나.. 어플리케이션 레벨의 락 용도로 충분히 써볼만 합니다. 모든 것은 각자의 문제 상황에 맞춰서 재미나게 이야기를 풀어보면 될 것 같네요. ㅎㅎ
“별 생각없이 넘어갈 수 있는 Affected Rows 도 병맛나게 활용해볼 수 있다”라는 이야기를 해보고 싶었어요.
좋은 밤 되세요, ㅎㅎ