Overview
FederatedX는 MariaDB에서 제공하는 확장된 기능의 Federated이며, 기본적으로 MariaDB에서는 별다른 옵션 없이 사용할 수 있습니다.
바로 이전 포스팅(http://j.mp/16VA8x6)에서는 이 FederatedX 엔진을 활용하여 대용량 테이블을 서비스에 큰 지장없이 이관을 했던 사례에 대해서 정리를 했었는데요. 이 경험을 바탕으로 서비스에서 조금 더 유용하게 활용할 수 있을 방안에 대해서 상상(?)을 해보았습니다.
즉, 지금부터는 FederatedX 엔진 관련된 테스트를 바탕으로 정리하는 내용이오니, 만약 실 서비스에 적용하고자 한다면 반드시 검증 후 진행하셔야 합니다. ^^
Why FederatedX?
단일 데이터베이스의 성능을 따지자면, 굉장한 퍼포먼스를 발휘하는 MySQL 이기는 합니다만.. SNS 서비스 환경에서는 결코 단일 서버로는 커버 불가능합니다. 이 상황에서는 반드시 샤딩(데이터를 분산 처리) 구조로 설계를 해야하는데, 한번 구성된 샤딩은 온라인 중에 변경하기가 참으로 어렵습니다.
서비스 순단을 발생할 수 있지만, 온라인으로 데이터를 재배치를 할 수 있는 방법은 없을까? 하는 생각을 하던 와중에, 저는 FederatedX 엔진에서 해답을 찾았습니다.
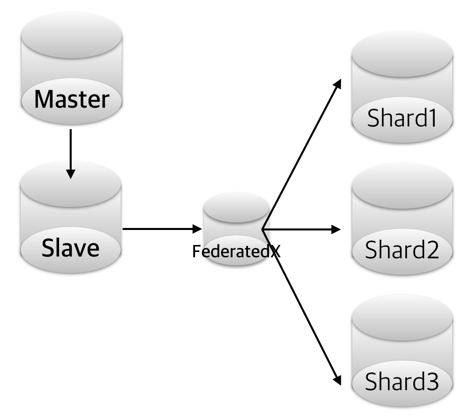
MariaDB에서 제공하는 FederatedX엔진은 MySQL에서 제공하는 기능 외에 트랜잭션 및 파티셔닝 기능이 확장되어 있는데, 이 두가지 특성을 활용한다면 앞선 그림처럼 기존 데이터 구조를 원하는 형태로 재배치할 수 있다는 생각이 번뜩 났습니다. ㅎㅎ
단, 아래에서 설명할 모든 상황들은 아래 4 가지 상황이어야한다는 가정이 필요합니다.
- 샤드 키 업데이트는 없어야 한다.
업데이터 시 기존 샤드 데이터가 DELETE되지 않음 - ALTER 작업은 없어야 한다.
FederatedX 스키마 변경 불가 - 샤드 키는 문자열 타입이어서는 안된다.
문자열로는 Range 파티셔닝 사용 불가 - 원본 서버 Binary Log은 ROW 포멧이어야 한다.
FederatedX 에서 일부 쿼리 미지원
ex) INSERT INTO .. ON DUPLICATE UPDATE
자, 각 상황에 맞게 이쁜(?) 그림으로 간단하게 살펴보도록 할까요?
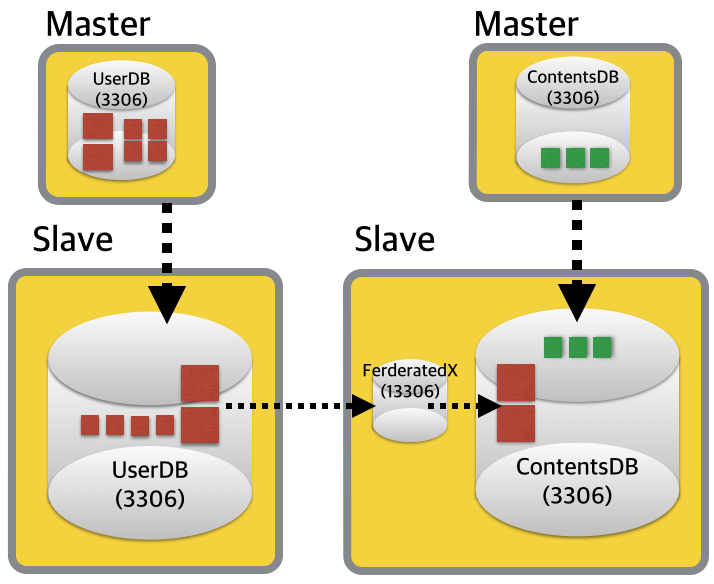
1) 샤드 재배치
기존 샤드를 재배치하는 경우인데, 만약 일정 범위(1~100, 101~200)로 데이터가 분산 저장되어 있는 경우를 해시 기준으로 변경하고 싶을 때 유용하게 적용가능할 것이라고 생각되는데요.
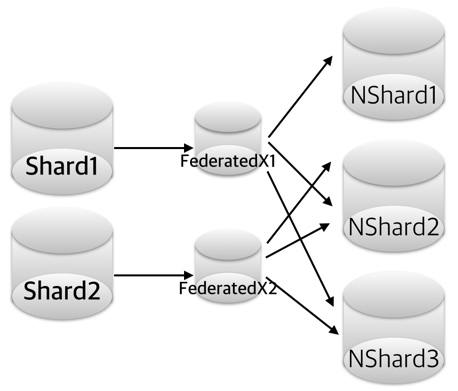
위 상황에서 FederatedX1과 FederatedX2을 다음과 같은 스키마 구성합니다.
CREATE TABLE `tab` ( `p_id` int(11) NOT NULL, `col01` bigint(20) NOT NULL, `col02` bigint(20) NOT NULL, PRIMARY KEY (`user_id`) ) ENGINE=FEDERATED PARTITION BY LIST (mod(p_id,3)) (PARTITION p0 VALUES IN (0) ENGINE = FEDERATED connection='mysql://feduser:fedpass@Nshard1_host:3306/db/tab', PARTITION p1 VALUES IN (1) ENGINE = FEDERATED connection='mysql://feduser:fedpass@Nshard2_host:3306/db/tab', PARTITION p1 VALUES IN (1) ENGINE = FEDERATED connection='mysql://feduser:fedpass@Nshard3_host:3306/db/tab');
원본 샤드 데이터를 각 FederatedX에 Import 후 리플리케이션 구성하면, 파티셔닝 정의에 맞게 데이터샤드들이 저장되겠죠? ^^
단, 데이터 동기화에 가장 큰 요소는 바로.. Network Latency입니다. 동일 IDC, 다른 스위치 장비에 물려있는 DB 경우에는 약 초당 500 ~ 700 rows정도 데이터 변경이 이루어졌습니다. 물론, 동일 스위치 경우에는 이보다 훨씬 더 좋은 데이터 변경 처리가 이루어질 것이라고 예측됩니다만.. 흠.. 이것은 기회가 된다면, 테스트하고 싶네요. ^^;;
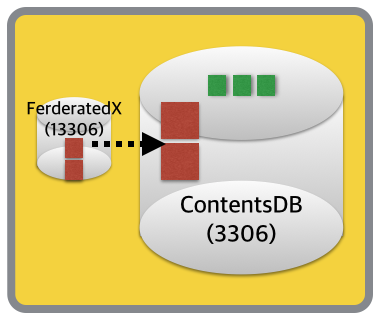
2) 로컬 데이터 재구성
아래와 같이 현재의 DB 혹은 테이블을 여러 개의 객체로 찢는 경우를 말할 수 있는데요, 앞서 치명적인 요소가 되었던 Network Latency는 이 상황에서는 별다른 문제가 되지 않습니다. 모든 통신이 메모리 상에서 이루어지기 때문에, 본연의 속도가 나올 수 있는 것이죠. ^^
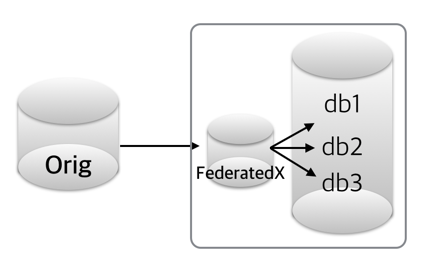
FederatedX 전용 서버를 다음과 같은 설정(/etc/my_fed.cnf)으로 구동하도록 합니다. 포트는 13306으로 띄운다는 가정으로..
[mysqld_safe] timezone = UTC [mysqld] port = 13306 socket = /tmp/mysql_fed.sock character-set-server = utf8 skip-innodb server-id = xxx binlog_format = row [client] port = 13306 socket = /tmp/mysql_fed.sock [mysql] no-auto-rehash default-character-set = utf8
FederatedX 전용 서버를 간단하게 아래와 같이 띄우면 되겠죠? ㅎ
/usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/my_fed.cnf
그후 아래와 같이 FederatedX 테이블을 생성 후 원본 테이블 데이터 Import 후 리플리케이션을 맺어주면, DB별로 데이터가 재배치된 샤드 형태가 완성됩니다. ^^
CREATE TABLE `tab` ( `p_id` int(11) NOT NULL, `col01` bigint(20) NOT NULL, `col02` bigint(20) NOT NULL, PRIMARY KEY (`user_id`) ) ENGINE=FEDERATED PARTITION BY LIST (mod(p_id,3)) (PARTITION p0 VALUES IN (0) ENGINE = FEDERATED connection='mysql://feduser:fedpass@127.0.0.1:3306/db1/tab', PARTITION p1 VALUES IN (1) ENGINE = FEDERATED connection='mysql://feduser:fedpass@127.0.0.1:3306/db2/tab', PARTITION p2 VALUES IN (2) ENGINE = FEDERATED connection='mysql://feduser:fedpass@127.0.0.1:3306/db3/tab');
테스트를 해보니 초당 수천 건 데이터 변경이 가능하며, 단일 서버 데이터 재배치에 가장 유용하게 활용될 수 있다고 생각되네요.
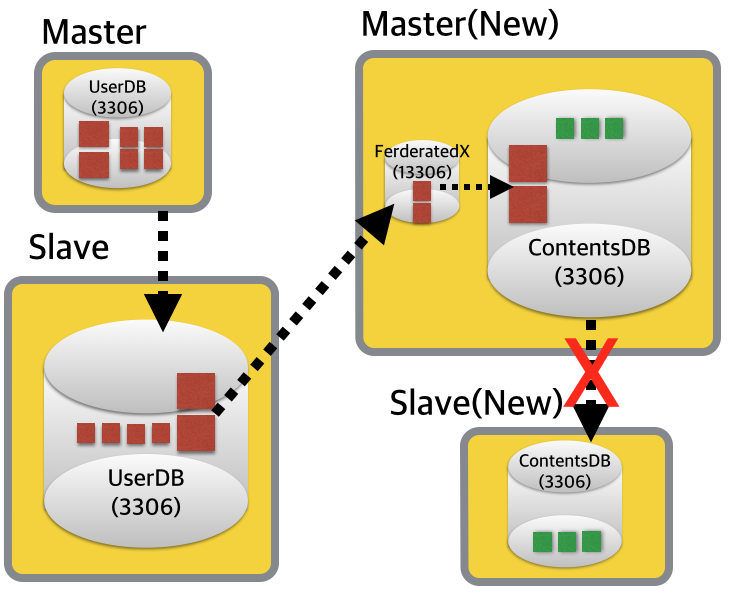
3) 데이터 통합
늘 서비스가 잘되면 참 좋겠지만.. 때로는 망해가는 서비스의 DB를 한곳으로 몰아야할 경우도 있습니다. ㅜㅜ 앞에서 설명한 것들을 이 상황에 맞게 조금만 수정을 하면 되니, 굳이 길게 설명은 하지 않도록 하겠습니다.
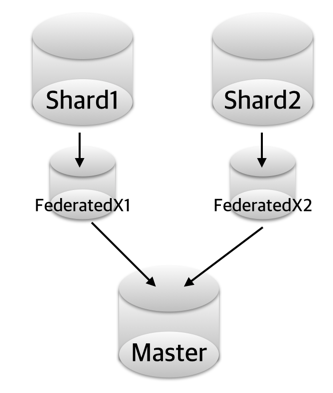
단, 기존 샤드의 데이터가 샤드키에 맞게 엄격하게 분리가 되어 있어야 합니다. (리플리케이션에서 충돌날 수 있어요!!)
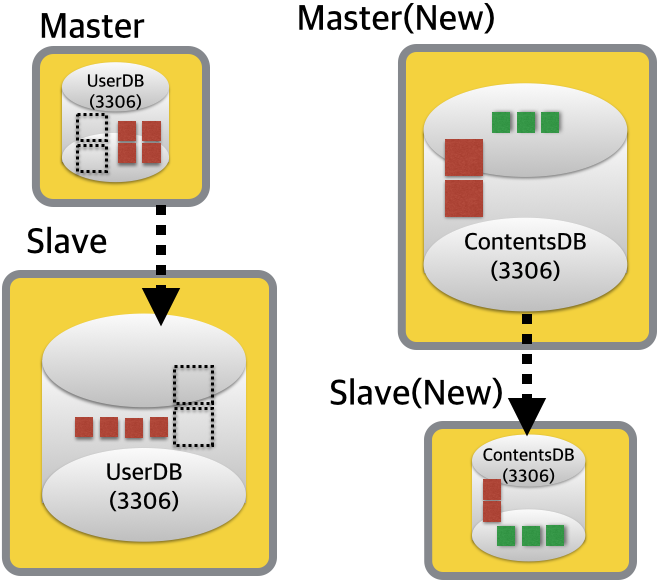
4) 아카이빙
수년을 보관해야하는 당장 정리가 불가한 콜드데이터 성격의 데이터를 한 곳에 모은다는 컨셉인데요.. 이에 대한 것은 사전에 안정성 테스트 반드시 필요합니다. (어디까지나 테스트를 바탕으로 활용 가능한 상황인지라.. ^^;;)
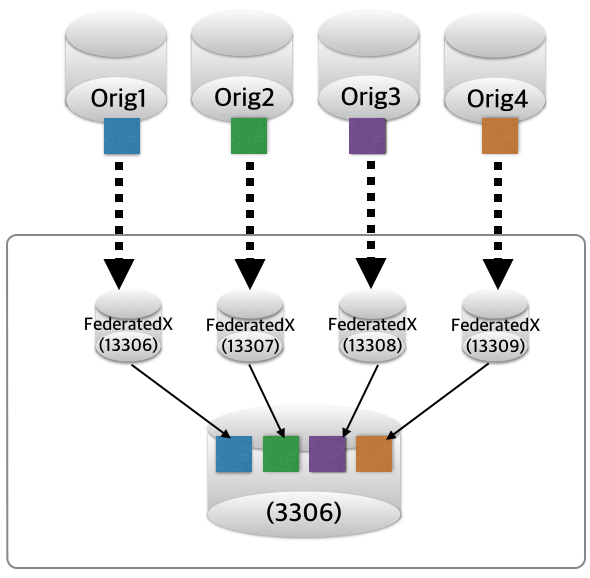
하루에 한번씩 돌아가면서 리플리케이션 IO_THREAD를 ON/OFF를 하게되면, 다수의 데이터베이스로부터 오는 데이터를 쉽게 한 곳으로 모을 수 있겠죠. 만약, 원본 테이블에서 파티셔닝 관리를 한다면, 이에 대한 에러 스킵 설정을 FederatedX에 미리 정의해놓으면 참 좋겠네요. ^^
Conclusion
처음에 버리다시피 전혀 검토를 하지 않았던 FederatedX를 다른 시각으로 발상을 전환해보니, 매우 활용할 수 있는 분야가 많았습니다. 물론 아직 실 서비스에서 직접 해보지는 않았지만, 이에 대한 각 테스트를 해보니 충분히 활용해볼 만한 여지는 있었습니다.
참고로, 위에서 설명하지는 않았지만, FederatedX +Blackhole을 활용하게 된다면, Network Latency 극복을 어느정도 할 수 있다고 생각합니다.
부족한 설명을 읽어주셔셔 감사합니다. ^^