안녕하세요. 오늘은 MySQL을 사용할 때 지켜야할 사항 몇 가지 정리합니다.
나름 혼자서 정리를 해 본 것들인데, MySQL로 서비스를 준비 중이라면 한 번쯤은 고려를 해봤으면 하는 내용입니다.^^
테이블 설계 시 유의 사항
1. 반드시 Primary Key를 정의하고 최대한 작은 데이터 타입을 선정한다.
- 로그 성 테이블에도 기본적으로 PK 생성을 원칙으로 함
- InnoDB에서 PK는 인덱스와 밀접한 관계를 가지므로 최대한 작은 데이터 타입을 가지도록 유지
2. 테이블 Primary Key는 auto_increment를 사용한다.
- InnoDB에서는 기본 키 순서로 데이터가 저장되므로, Random PK 저장 시 불필요한 DISK I/O가 발생 가능
- InnoDB의 PK는 절대 갱신되지 않도록 유지
(갱신 시 갱신된 행 이후 데이터를 하나씩 새 위치로 옮겨야 함)
3. 데이터 타입은 최대한 작게 설계한다.
- 시간정보는 MySQL데이터 타입 date/datetime/timestamp 활용
- IP는 INET_ATON(‘IP’), INET_NTOA(int) 함수를 활용
- 정수 타입으로 저장 가능한 문자열 패턴은 최대한 정수 타입으로 저장
4. 테이블 내 모든 필드에 NOT NULL 속성을 추가한다.
- NULL을 유지를 위한 추가 비용 발생
(NULL 허용 칼럼을 인덱싱 할 때 항목마다 한 바이트 씩 더 소요)
5. Partitioning을 적절하게 고려하여 데이터를 물리적으로 구분한다.
- 데이터 및 인덱스 파일이 커질수록 성능이 저하되므로Partitioning 유도
- PK 존재 시 PK 내부에 반드시 Partitioning 조건이 포함되어야 함
인덱스 설계 시 유의 사항
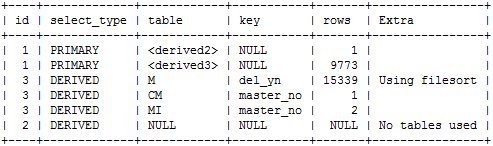
1. 인덱스 개수를 최소화 한다.
- 현재 인덱스로 Range Scan이 가능한지 여부를 사전에 체크
- 인덱스도 서버 자원을 소모하는 자료구조이므로 성능에 영향을 줌
2. 인덱스 칼럼은 분포도를 고려하여 선정한다.
- 인덱스 칼럼 데이터의 중복이 줄어들수록 인덱스는 최대의 효과를 가짐
- 하단 쿼리 결과 값이 1에 가까울수록(0.9이상 권고) 인덱스 컬럼으로 적합함
SELECT count(distinct INDEX_COLUMN)/count(*)
FROM TABLE;
3. 커버링 인덱스(Covering Index)를 활용한다.
4. 스토리지 엔진 별 INDEX 특성을 정확히 인지한다.
- InnoDB에서 데이터는 PK 순서로 저장되고, 인덱스는 PK를 Value로 가짐
- MyISAM은 PK와 일반 인덱스의 구조는 동일하나, Prefix 압축 인덱스를 사용
(MyISAM 엔진에서 ORDER BY 시 DESC는 가급적 지양)
5. 문자열을 인덱싱 시 Prefix 인덱스 활용한다.
- 긴 문자열 경우 Prefix 인덱스(앞 자리 몇 글자만 인덱싱)를 적용
CREATE INDEX IDX01 ON TAB1(COL(4), COL(4))
- Prifix Size는 앞 글자 분포도에 따라 적절하게 설정
(하단 결과가 1에 가까울 수록 최적의 성능 유지, 0.9이상 권고)
SELECT count(distinct LEFT(INDEX_COLUMN,3))/count(*)
FROM TABLE;
6. CRC32함수 및 Trigger를 활용하여 인덱스 생성한다.
- URL/Email같이 문자 길이기 긴 경우 유용
- INSERT/UPDATE 발생 시 Trigger로 CRC32 함수 실행 결과 값을 인덱싱
- CRC32 결과값을 저장할 칼럼 추가 및 인덱스 생성
alter table user_tbl add email_crc int unsigned not null;
create index idx01_email_crc on user_tbl (email_crc);
create trigger trg_user_tbl_insert
before insert on user_tbl
for each row
begin
set new.email_crc = crc32(lower(trim(new.email)));
end$
create trigger trg_user_tbl_update
before update on user_tbl
for each row
begin
if old.email <> new.email then
set new.email_crc = crc32(lower(trim(new.email)));
end if;
end$
select *
from user_tbl
where email_crc = crc32(lower(trim('mail@domain.com')))
and email= 'mail@domain.com'
CRC32 결과가 중복되어도, email값을 직접 비교하는 부분에서 중복이 제거됩니다.
[Read More]