Overview
안녕하세요. 요새 창고 대방출! 그동안 미뤄 두었던 얘기들을 연달아 공유합니다. (마스터 스크립트를 만들어야하는 수고를 덜기 위해.. 해당 스크립트 제거 및 스크립트 수정하였습니다.)
MySQL을 사용하는 이상, 리플리케이션 활용에서 벗어나기 쉽지 않은데요. 그 말은 곧 다수의 동일한 데이터를 가진 여러개의 서버를 운영관리 해야한다는 말과 같고.. 장비가 많아진다는 것은 그만큼 데이터 복구가 많다는 이야기이기도 하지요. 특히나 샤딩 환경으로 데이터 폭증을 대비해두었다면 더욱 그렇습니다.
게다가 복구 시 새벽 백업을 사용한다는 말은 곧 새벽 이후로 저장이된 변경 이력을 일괄 적용을 해야하고.. 이 내용이 많으면 데이터 동기화 시간도 적지않게 소모되고.. (횡설수설~)
이런 환경 속에서 세상 만사가 귀찮은 DBA를 위해.. 복구 자동화 방안에 대해 간단하게 얘기를 해봅니다.
Prepare
아.. 크게 중요한 것은 아니고.. 제가 구성을 한 환경입니다. 뭐.. “Linux+MySQL+Xtrabackup”이 되는 환경이면 큰 이슈는 없다는 생각이.. ^^ (단, Xtrabackup은 MySQL5.7 데이터를 백업 가능해야합니다.)
- CentOS 6.8
- MySQL 5.7.14
- Xtrabackup-2.4.3
- pv
그리고 일단 저는 소심하기 때문에.. GTID가 아닌 기존 Binlog Position 기반의 리플리케이션 기준으로 데이터 복제를 하도록 구성하였습니다. 🙂
그리고 문제없이 데이터를 땡겨오는 수단으로.. SCP를 활용할 것인데.. 이 말은 곧 인증 관련하여 패스워드 없이 데이터를 땡겨올 수 있도록 미리미리 id_rsa.pub 키를 리플리케이션 노드끼리 페어링해놓도록 합시다. 즉.. 패스워드 없이 아래와 같이 서버 접근이 되도록 준비해야한다는 것이죠. (이 부분은 패스~)
server1$ ssh mysql@server2
server2$ ssh mysql@server1
Restore Scenario
서비스의 특성 혹은 개개인의 선호도에 따라 다르겠지만.. 제가 가장 중요시한 가치는 일순위는 역시 복구 효율성입니다. 물론, 효율성 이전에 서비스 영향도는 거의 없어야 하겠죠. ㅜㅜ 그렇다면, 당연한 이야기겠지만.. 데이터 전송 트래픽에 대한 조절 방안도 필요하겠죠.
일반적으로 복구를 하는 케이스라면, 두 가지 경우를 생각해볼 수 있습니다.
- restore from master data
마스터의 데이터로 슬레이브를 추가하는 케이스로.. 받아온 서버의 Binlog 포지션이 슬레이브 구성의 정보가 됩니다. - restore from slave data
슬레이브의 데이터로 슬레이브를 구성하는 케이스로.. 현재 슬레이브와 동일한 슬레이브를 하나 더 추가하는 케이스입니다. 데이터를 받아오는 슬레이브의 Slave Status 정보가 복구 슬레이브의 구성 정보가 됩니다.
진행하기에 앞서서 양해의 말씀을 드리자면.. 이 자리는 어디까지나 자동 복구 시나리오를 설명하는 공유의 장이지.. 현재 날코딩으로 제가 꾸역꾸역 구현한 스크립트를 공유하는 자리는 아니랍니다. ^^ 뭐. 너저분한 코드 정리를 하게 되고.. 이것저것 엮인 것들을 심플하게 풀어놓을 수 있다면 얘기가 달라지겠지만.. 전 귀찮아하는 DBA이기에.. Validation Check 혹은 패스워드 암호화 같은 설명은 모두 스킵하였습니다. ㅋㅋ
그리고 데이터 복구 사전 지식으로.. Xtrabackup의 하단 매뉴얼을 먼저 읽어보심 큰 도움이 되리라 확신합니다.
https://www.percona.com/doc/percona-xtrabackup/2.4/howtos/setting_up_replication.html
자. 그럼 이야기를 풀어볼까요?
case 1) restore from master data
앞서 얘기한대로.. 마스터로부터 데이터를 받아서, 바로 하단에 슬레이브를 구성하는 케이스로.. 하단 이미지와 같은 모습으로 데이터를 구성하는 케이스입니다.
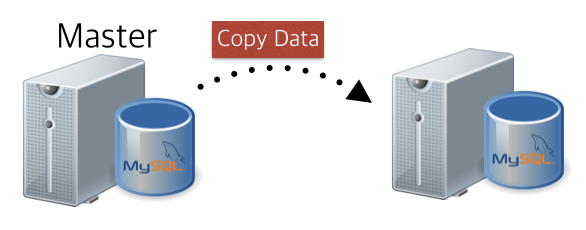
1) 데이터 끌어오기
Xtabackup의 마지막 과정 중.. InnoDB가 아닌 데이터를 카피하는 과정이 있는데.. “–no-lock” 옵션을 주지 않으면, 데이터 정합성 보장을 위해 데이터 카피하는 동안 글로벌 Lock을 걸고 수행하게 됩니다. 즉.. 서비스에 영향을 준다는 말이겠지요.
innobackupex 부분을 바로 쉘에 넣어서 한방에 수행하도록 아래와 같이 작성합니다.(로컬 백업 습관으로.. 대충 변경했더니.. 생각이 없었네요. ㅋㅋ) 스트리밍으로 전송되는 백업 데이터를 pv로 제어(초당 50메가, 바쁜 서버는 더욱 약하게)하고..
ssh -o StrictHostKeyChecking=no mysql@${TARGET_HOST} \
"innobackupex \
--host="127.0.0.1" \
--user=backupuser \
--password="backuppass" \
--no-lock \
--stream=xbstream \
/data/backup | pv --rate-limit 50000000" 2> innobackupex.log \
| xbstream -x 2> xbstream.log
innobackupex.log와 xbstream.log 두 곳의 로그를 보고, 받아온 백업 데이터 유효성을 검수할 수 있습니다. innobackupex.log에는 “completed OK!” 로 끝이 나야 정상적으로 데이터를 받아온 것이고, xbstream.log결과에는 아~무런 내용도 없어야 제대로 스트리밍을 풀어냈다고 볼 수 있어요.
2) 리두로그 적용하기
앞선 과정이 정상적으로 수행되었다는 가정 하에 진행하는 것으로.. 데이터가 백업 및 전송되는 동안 변경된 데이터를 적용하는 과정입니다. 이 역시 innobackupex.log의 마지막이 “completed OK!” 로 끝이 나야 정상적으로 로그가 적용된 것으로 볼 수 있습니다.
innobackupex --apply-log . 2>> innobackupex.log
3) 슬레이브 구성하기
마지막으로.. 실제 슬레이브로 구성할 마스터의 포지션을 추출하는 과정으로.. apply log 이후 생성이 되는 “xtrabackup_binlog_pos_innodb” 에서 위치 정보를 아래와 같이 추출합니다. 보통은 아래와 같이 탭으로 구분하여 마스터의 바이너리 로그 포지션이 기록되어 있는데..
mysql-bin.000001 481
저는 아래와 같이 sed 명령을 통해서 조금 있어보이게(?) 로그 포지션을 정의하였습니다. awk든 뭐든.. 편한 방법으로.. ^^
MASTER_LOG_FILE=`sed -r "s/^(.*)\s+([0-9]+)/\1/g" xtrabackup_binlog_pos_innodb`
MASTER_LOG_POS=`sed -r "s/^(.*)\s+([0-9]+)/\2/g" xtrabackup_binlog_pos_innodb`
자. 이제, 마스터 서버도 정해졌고, 리플리케이션 구성을 위한 바이너리 로그 포지션도 정해졌으니.. 아래와 같이 슬레이브를 구성해보도록 해봅시다.
echo "change master to
master_host='${TARGET_HOST}',
master_user='repl',
master_password='replpass',
master_log_file='${MASTER_LOG_FILE}',
master_log_pos=${MASTER_LOG_POS};
start slave;"\
| mysql -uroot -pxxxxxx
이렇게 하면 큰 무리 없이 아래와 같이 마스터 데이터를 활용하여 신규 슬레이브를 구성 완료입니다.
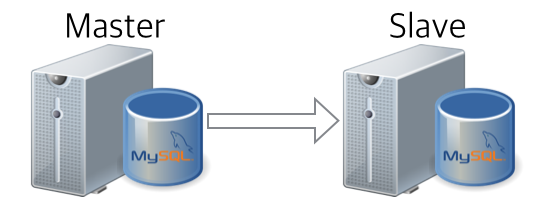
case 2) restore from slave data
두번째 케이스.. 현재 위치한 슬레이브 서버의 데이터를 활용하여 신규 슬레이브 서버를 추가하는 케이스인데.. 아래와 같은 데이터 흐름을 가집니다. 정상적으로 구동 중인 슬레이브 서버로부터 데이터를 가져와서, 해당 슬레이브의 슬레이브 정보를 바탕으로 동일한 위상의 추가 슬레이브를 구성하는 시나리오죠. (말이 참 어렵죠? ㅋ)
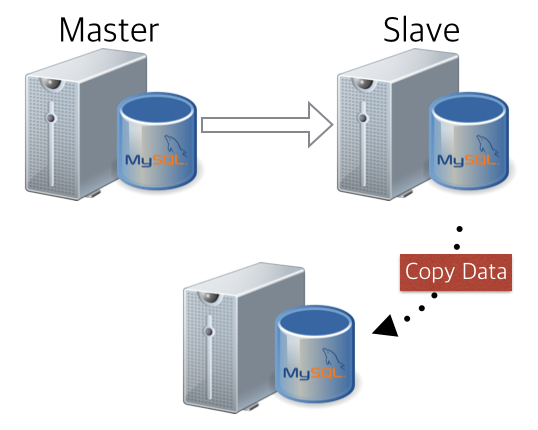
1) 데이터 끌어오기
이번에는 슬레이브로부터 받아온 백업 스트리밍 데이터를 바로 xbstream으로 풀어버리는 과정으로, 마찬가지로 pv로 전송량 제어를 하였습니다. 어차피 슬레이브이니.. 서비스 투입된 장비가 아니라면.. 기가비트로 땡겨와도 문제 없으니.. 굳이 안써도 될 것 같지만..;;
앞 게이스와 다르게 슬레이브 포지션을 받아올 목적으로 아래와 같이 ” –slave-info” 옵션을 지정해줍니다. (이 옵션을 줘야, 슬레이브 상태를 기록합니다.)
ssh -o StrictHostKeyChecking=no mysql@${TARGET_HOST} \
"innobackupex \
--host="127.0.0.1" \
--user=backupuser \
--password="backuppass" \
--slave-info \
--stream=xbstream \
/data/backup | pv --rate-limit 50000000" 2> innobackupex.log \
| xbstream -x 2> xbstream.log
마찬가지로 innobackupex.log와 xbstream.log 두 곳의 로그를 보고, 받아온 백업 데이터 유효성을 검수할 수 있습니다. innobackupex.log에는 “completed OK!” 로 끝이 나야 정상적으로 데이터를 받아온 것이고, xbstream.log결과에는 아~무런 내용도 없어야 제대로 스트리밍을 풀어낸 것이죠.
2) 리두로그 적용하기
데이터가 백업 및 전송되는 동안 변경된 데이터를 적용을 이전과 마찬가지로 동일하게 수행을 합니다. 이 역시 innobackupex.log의 마지막이 “completed OK!” 로 끝이 나야 정상적으로 처리된 것입니다.
innobackupex --apply-log . 2>> innobackupex.log
3) 슬레이브 구성하기
슬레이브 포지션은 이제.. 앞서 마스터에서 추출한 것과는 조금 다르게 정의를 해야하는데.. 먼저 바이너리 로그 포지션은 “xtrabackup_slave_info”에서 찾아내야 합니다.
마지막으로.. 실제 슬레이브로 구성할 마스터의 포지션을 추출하는 과정으로.. apply log 이후 생성이 되는 “xtrabackup_binlog_info” 에서 위치 정보를 아래와 같이 추출합니다. 보통은 아래와 같이 탭으로 구분하여 마스터의 바이너리 로그 포지션이 기록되어 있는데.. 실제 아래와 같은 형태로 저장이 되어 있지요.
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=481
아래와 같이 정규식으로 로그 파일과 포지션을 가져와 보겠습니다.
MASTER_LOG_FILE=`sed -r "s/(.*)MASTER_LOG_FILE='(.*)', MASTER_LOG_POS=([0-9]+)/\2/g" xtrabackup_slave_info` MASTER_LOG_POS=`sed -r "s/(.*)MASTER_LOG_FILE='(.*)', MASTER_LOG_POS=([0-9]+)/\3/g" xtrabackup_slave_info`
여기까지 바이너리 로그 포지션을 가져오는 것은 큰 무리 없이 진행을 하였는데.. 문제는 실제로 리플리케이션을 맺어야하는 서버에 대한 정보를 어디서 가져와야하냐는 것에 있습니다. 물론 이것을 별도의 모니터링 툴에서 추출을 하거나.. 혹은 주기적으로 어딘가에 마스터 정보를 밀어넣거나 할 수 있겠지만.. 제가 택한 방식은 데이터를 땡겨온 타겟 슬레이브 장비에 들어가서 직접 Slave Status를 조회해서, 현재 바라보고 있는 마스터 서버 정보를 가져오는 방식이었습니다.
MASTER_HOST=`mysql -urepl -preplpass -h ${TARGET_HOST} -e 'show slave status\G' | grep 'Master_Host: ' | sed -r 's/\s*(Master_Host: )//g'|sed -r 's/\s*//g'`
한가지 불만은.. Xtrabackup에서 xtrabackup_binlog_info 파일을 생성을 할 때, 왜 슬레이브에서 바라보고 있는 마스터 정보를 기록해주지 않는가..이지만.. 이건 뭐 솔루션이고.. 그들만의 철학이 있다고 생각으로~ 제가 조금 더 귀찮아짐을 택하기로 했습니다.
자. 이제, 마스터 서버도 알아냈고, 리플리케이션 구성을 위한 바이너리 로그 포지션도 정해졌으니.. 아래와 같이 슬레이브를 구성해보도록 해봅시다. 실제 마스터의 호스트가 타겟 호스트가 아닌, 마스터 호스트(앞에서 알아낸) 정도가 변경되었습니다.
echo "change master to
master_host='${MASTER_HOST}',
master_user='repl',
master_password='replpass',
master_log_file='${MASTER_LOG_FILE}',
master_log_pos=${MASTER_LOG_POS};
start slave;"\
| mysql -uroot -pxxxxxx
자~ 여기까지 되면.. 아래와 같이 슬레이브로부터 데이터를 받아와서~ 동일한 레벨의 슬레이브 구성 성공입니다.
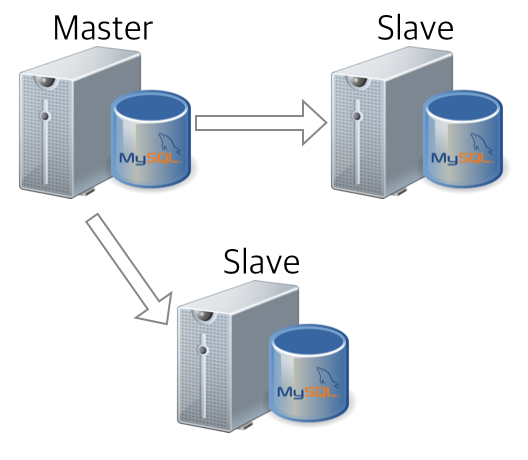
Conclusion
지금까지, 현재 돌고 있는 데이터를 활용하여 슬레이브를 구성하는 방법에 대해서 알아보았습니다. 시작하기 전에 양해의 말씀을 드린 것처럼, 스크립트를 모두 풀어서 보여드릴 수는 없었습니다. 물론 몇백라인정도밖에 안되는 간단하다면 간단한 스크립트이기는 하나.. 이것이 정답일 수 없기 때문이지요. (세트로 묶어서.. 범용적으로 조금 사용할 수준이 되면.. 공개는 그때 해보도록 할께요. ^^)
SCP로 데이터를 땡겨오지 않고, nc 유틸을 통해 받아올 수도 있는 것이고.. 고전적인 Binlog 포지션이 아닌.. GTID를 통해 더욱 심플하게 해결할 수도 있겠죠.
제 방안은 한 사례일 뿐.. 그 이상도 이하도 아닙니다. 그래서 편하게 제가 생각하는 이 데이터 흐름을 다른 세상만사 귀찮은 DBA분들이 더욱 완성도 있는 그림을 그려주면 좋겠다는 바램으로.. 공유하였습니다. 쿨럭~
(근데.. 이것 시스템화 해놓고 보니.. 정말 시간 많이 잡아먹고.. 손 많이 가는 노가다 작업이 줄어서.. 일도 많이 줄어버렸네요~ 크항~!)
긴~글, 늦은밤 이만 마무리 하겠습니다. ^^