이 글은 제가 MySQL Power Group에 예전에 포스팅한 자료입니다.
참고 : http://cafe.naver.com/mysqlpg/189
과거와는 다르게 데이터 사이즈가 비약적으로 커지고 있습니다. 특히, 최근 들어 SNS 서비스가 성황을 이루면서, 개인화된 데이터는 날이 갈수록 기하 급수적으로 늘어나고 있습니다. 최근 Fratical Index 기반의 TokuDB가 오픈 소스로 풀리면서 재조명을 받고 있는데, 이에 대해서 간단하게 설명해보도록 하겠습니다.
B-Tree?
TokuDB에 논하기에 앞서, 전통적인 트리 구조인 B-Tree에 대해 알아보도록 하죠.
일반적으로 RDBMS에서 인덱스는 대부분 B-Tree기반으로 동작하는데, 크게는 “Internal Node”와 “Leaf Node”로 나뉩니다. Internal Node는 데이터를 어느 방향(작으면 왼쪽, 크거나 같으면 오른쪽)으로 보낼 지 결정하는 Pivot과 다음 Pivot의 위치를 알려주는 포인터로 구성됩니다. Internal Node의 가장 마지막 포인터는 Leaf Node를 향하는데, Leaf Node에는 보통은 데이터가 저장이 되죠.
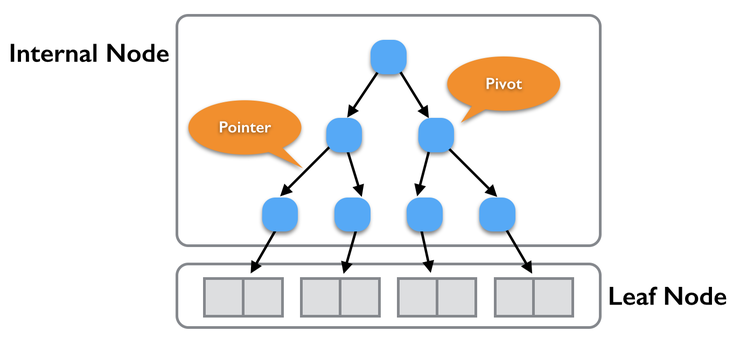
Leaf Node는 트리 특성대로 왼쪽에서 오른쪽으로 순서대로 데이터가 저장되어 있습니다. 이러한 특성으로 트리로 구성된 구조에서는 데이터를 특정 범위를 가져올 수 있는 Range 처리가 가능하죠.
B-Tree는 데이터가 증가를 해도 Pivot을 거치는 횟수가 일정 수치 이상으로는 늘어지는 않습니다. 물론 Pivot 수와 Leaf Node 수는 데이터 증가 수와 비례하여 선형적으로 늘어날 수도 있겠지만, 원하는 Leaf Node에 접근하기 위해 거치는 Pivot 수는 크게 늘지는 않습니다. (비용으로 따진다면.. 1회 데이터 접근이 O(logN)라는 수치가.. 신경은 안쓰셔도 됩니다. ^^)
위 트리에서 Leaf Node에 접근하기 위해 거치는 Pivot 수는 3입니다. 만약 Leaf Node가 8개로 늘어나게 되면 거쳐야 하는 수는 4번이고, 16개이면 5번이 됩니다. 즉, Leaf Node 수(데이터 사이즈)가 현재 수보다 2배 사이즈가 되어야 1회 더 거치게 되는 것이죠.
Leaf Node는 키 순으로 저장이 되어 있다는 것과 Pivot을 통한 데이터 접근이 가능한 B-Tree의 특성으로 단 건 데이터 접근과 특정 범위 처리에 좋은 성능을 보여줍니다.
그러나, 데이터 사이즈가 커지게 되면 B-Tree에도 큰 문제점에 봉착하게 되는데, 메모리 자원은 한계가 있다는 점입니다. 데이터가 커지면 모든 데이터를 메모리에 위치할 수가 없겠죠. 메모리 자원은 한정적이기 때문에, Leaf Node의 대부분은 디스크에 존재할 가능성이 크다. Leaf Node가 디스크에 존재하는 비율이 높아질 수록 해당 데이터를 Read/Write 시 잦은 Disk I/O가 발생할 수 밖에 없습니다.
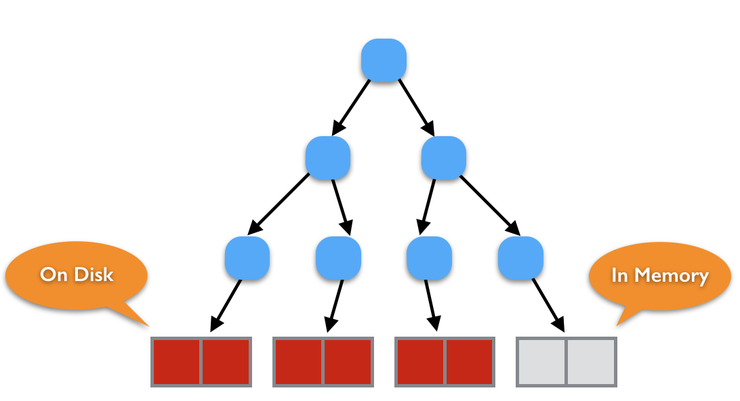
컴퓨터 시스템 내부에서 가장 느린 성능을 보여주는 것은 바로 디스크로부터 Read/Write을 수행하는 것인데요.. 아무리 좋은 알고리즘을 가지고 데이터를 처리한다 하여도, 잦은 디스크 접근을 통해 동작하게 되면, 게다가 그 동작이 순서가 보장되지 않는 랜덤한 디스크 블록을 읽어야하는 이슈라면 결코 성능이 보장되지 않습니다.
B-Tree 특성 상 트리에 데이터 유입 시 바로 반영을 해주어야 하기 때문에, 메모리가 부족하게 되면 Disk Read/Write에서 즉시 성능 병목 현상이 발생할 수밖에 없는 것이죠.

아무리 CPU 자원이 남아돌아도, Disk I/O Wait으로 인해 처리할 데이터를 메모리에 로딩하지를 못하면, 의미없는 상태입니다. 디스크로부터 데이터를 읽어와야 요청을 처리할 수 밖에 없기 때문이죠. 잦은 Disk I/O Wait.. 이것은 성능 저하를 유발하는 가장 큰 요소입니다.
tokutek에서는 이러한 잦은 디스크 I/O로 인한 문제를 해결하고자 새로운 해결법은 제시하였는데, 그것은 바로 “Fractal Tree”입니다.
Fractal Tree?
그렇다면 Fractal Tree란 무엇일까요?
Fractal Tree는 “Big I/O”에 촛점을 맞춘 자료 구조로, 잦은 Disk I/O를 줄이고, 한번에 다량의 데이터를 하단 노드로 전달함에 따라 데이터가 많은 상황에서도 효과적으로 처리할 수 있는 방안을 제시합니다.
Fractal Tree의 생김새는 B-Tree와 크게 다르지는 않습니다. Fractal Tree는 B-Tree와 같이 Internal Node와 Leaf Node로 구성되어 있고, Leaf Node에는 일반적으로 데이터가 저장되어 있습니다. Internal Node는 데이터를 어느 방향(작으면 왼쪽, 크거나 같으면 오른쪽)으로 보낼 지 결정하는 Pivot과 다음 Pivot의 위치를 알려주는 포인터로 B-Tree와 마찬가지로 구성되나 한가지 특이한 점이 더 추가됩니다. 바로 각 Pivot에는 “Buffer 공간”이 있다는 점이죠.. 바로 아래 그림처럼 말이죠. ^^
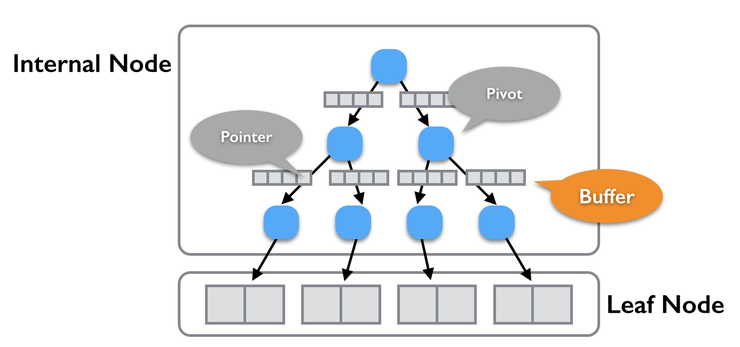
데이터가 유입되면, B-Tree처럼 바로 데이터를 Child Node(Pointer가 가리키는 Node)로 전달하지 않고, Buffer 공간에 저장을 합니다. 그리고 Buffer에 데이터가 가득 차는 순간 Buffer에 쌓인 데이터를 Child Node로 전달하게 됩니다. 버퍼를 어떻게 Child Node에 넘기는 지에 대한 내용은 스킵.. (쵸큼 많이 복잡해서.. 그림 그리기가 힘들어요. ㅠㅠ)
하단 이미지의 왼쪽 트리를 보면, 각 노드마다 버퍼 공간(회색 사각형)이 있습니다. 이 버퍼는 메모리 상에 존재하는 별도의 공간이며, 데이터가 유입 시 바로 자식 노드로 데이터를 내려보지 않고, 일시적으로 버퍼 공간에 보관을 합니다. 만약 하단 트리에서 2, 22 데이터가 유입되면(오른쪽 이미지 참고), 22 노드의 자식 노드로 바로 데이터를 내리지 않고 일시적으로 보관하고 있음을 보여줍니다. (버퍼는 최대 2개의 데이터를 저장할 수 있다고 가정!!)
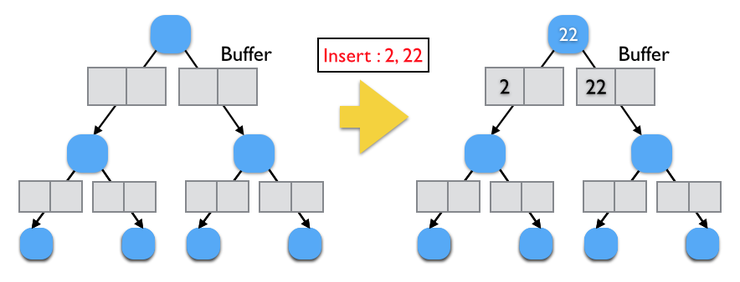
이 상태에서 추가로 99 데이터가 들어오게 되면, 하단 그림 1)번과 같이 오른쪽 버퍼 공간에 채워지게 됩니다. 이후 23 데이터가 들어오면, 오른쪽 버퍼에 더 이상 공간이 없게 되므로, 이 순간 데이터를 자식 노드로 내리게 되죠. 이 단계에서 Disk I/O가 발생할 수는 단계이다. 버퍼 공간이 확보되면, 23을 다시 빈 버퍼 공간에 넣게 되며, 최종적으로 23이 Fractal Tree에 저장되게 됩니다.
즉, B-Tree에서 데이터 유입시 매번 자식 노드로 데이터를 보내며 발생하던 잦은 Disk I/O 수가 Fractal Tree에서는 각 노드에 존재하는 버퍼 공간으로 인해 극적으로 감소합니다. 실제로 TokuDB를 사용하고 테스트 데이터를 생성하는 동안, TokuDB의 데이터 사이즈 변화가 크지 않음에 처음에는 의아하기도 하였어요. ^^
한번에 Disk I/O가 발생하기에 얻을 수 있는 점은 I/O 횟수 외에 추가로 더 있습니다. B-Tree에서는 잦은 Random Insert시 Leaf Node의 블록이 단편화되는 현상이 잦아들 수 있겠지만, Fractal Tree에서는 뭉쳐서 Disk I/O를 수행하므로 압축률이 좋을 뿐만 아니라 블록 단편화가 훨씬 줄어들게 되는 것이죠. 물론 InnoDB에서 Barracuda로 압축 포멧으로 테이블을 구성할 수는 있겠지만, 블록 단편화가 많아지는 경우 압축률이 저하될 수밖에 없기에, 얻는 것보다는 오히려 잃는 것이 더 많아질 수 있습니다.ㅜㅜ

TokuDB에서 Fractal Tree Index는 Message 기반으로 동작을 합니다. 데이터 변화가 발생하더라도, 즉시 Leaf Node로의 전달이 일어나는 것이 아닌, 발생했던 이벤트를 각 노드가 가지는 Buffer에 순차적으로 붙이고, 버퍼가 가득 차게 되면, 자식 노드로 버퍼에 저장된 메시지를 전달합니다.
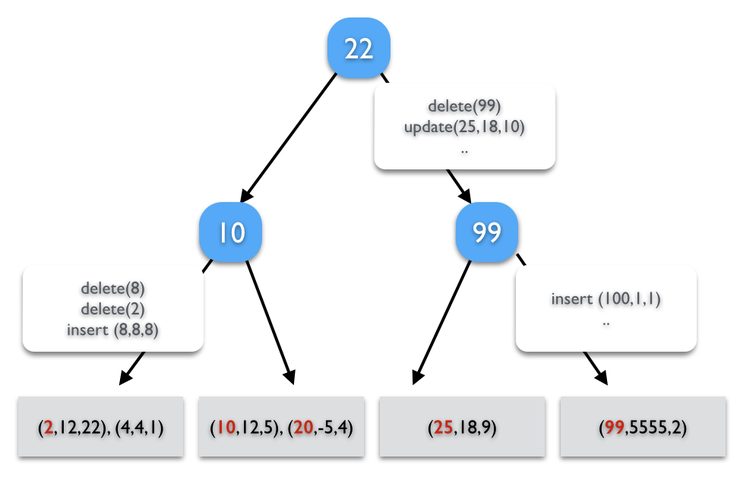
위 그림에서 가장 마지막에 수행된 연산은 99번 데이터를 지우라는 것이나, 실제로 Leaf Node에서 즉시 지워지지 않습니다. 이에 대한 이벤트는 메시지 형태로 버퍼에 저장이 되고, 관련 내용은 언젠가는 Leaf Node로 전달되어 적용될 것입니다.
자~! 야심한 이 밤!! 여기까지 정리하도록 하겠습니다. ^^
사실 B-Tree와는 컨셉이 조금 다른지라, 많이 헤매기도 했었지만.. 그림을 그리다보니 여기까지 오게되었네요. -_-;;
저와는 조금 다르게 생각하시는 분은 언제든지 제게 지적질을 해주세요!! 원래 지적 받으며 성장하기 마련..쿨럭~!
예전 포스팅을 새삼 여기에 붙인 이유는 무엇일까요? TokuDB에 대한 내용 2탄을 작성하기 위해서죠. ^^ 어쩌다 보니, TokuDB 를 조금 더 깊에 테스트하게 되었는데, 조만간 정리하여 블로그에 포스팅하도록 하겠습니다.